线上问题排查:10 大场景 + Arthas / JDK / 日志三件套,从应急止血到根因根治
Java Web 微服务系列 · 第 11 篇 · 线上问题排查
阅读时长:约 90 分钟
本文写于 2026 年 6 月
引子:凌晨 3 点 47 分的那通电话
2025 年 11 月 17 日凌晨 3 点 47 分,我被一连串急促的电话铃声叫醒。电话那头是某电商平台的运维总监,声音发颤:“哥,订单服务挂了,503 一片红,监控显示 JVM 老年代 99%,但我们 3 个工程师都搞不定,能远程支援一下吗?”
我一边穿衣服一边远程连上去,看到的景象触目惊心:
- CPU 单核打满到 99.8%,而且是其中 4 个核都满
- 堆内存 Old Gen 98%,且每秒都有 Young GC
- GC 日志 5 分钟内出现了 23 次 FullGC,每次 STW 2.4 秒
- 线程数 1425 线程,其中 800+ 状态是
BLOCKED,全部卡在同一个 synchronized 锁上 - 接口 RT 从正常的 80ms 飙升到 14 秒
- 告警群 已经被刷屏 800 多条,告警风暴本身又触发了 IM 服务的限流
事后排查,这是一张典型的"业务高峰期突遇死循环 + 缓存击穿 + 慢 SQL 雪崩"的复合故障——单一问题都还好处理,叠加在一起,3 个工程师根本反应不过来。
那次事故直接损失 47 万元。我开复盘会时说过一句后来被团队当成内部黑话的话:
“线上问题不会按教科书的方式出现,它会挑你最薄弱的环节同时打你 5 个地方。”
那天凌晨的应急动作,我记得很清楚——
- 03:50:收到告警,远程连服务器
- 03:55:确认 P0(订单服务不可用),启动应急群
- 04:00:K8s 把问题 Pod 摘流量,业务降级
- 04:10:用
jstack + top -Hp 定位到死锁 - 04:20:紧急重启 + 临时回滚到稳定版本
- 04:35:服务恢复,损失控制
- 04:50:复盘开始,写 Postmortem
整整 1 小时,其中** 60% 的时间花在了"找根因"上**。如果当时团队有一套成熟的 SOP(Standard Operating Procedure),MTTR 可以从 1 小时压到 15 分钟。
从那以后,我开始系统化地总结 Java 微服务线上的 10 大典型场景,并把 Arthas / JDK 自带工具 / 日志体系沉淀成团队应急 SOP。这篇文章,是这套 SOP 的完整公开版。
本文要回答三个问题:
- 10 大线上场景怎么识别、怎么应急、怎么定位、怎么根治?
- Arthas + JDK + 日志三件套在每个场景下分别怎么用?
- 如何搭建一套 5 层防御体系,把"出事故"变成"低概率事件"?
全文 18000+ 字,一次把 Java 微服务线上排查讲透。建议先收藏,遇到事故时按场景检索。
💡 我的阅读建议
- 第一次读:按章节顺序,建立体系(90 分钟)
- 遇到事故:直接定位到对应场景,按 Runbook 走(5-30 分钟)
- 日常复习:重点看方法论 + 5 层防御(30 分钟)
- 面试准备:重点看工具命令 + 备选方案对比(60 分钟)
一、排查方法论:先讲思路,再讲工具
工具是死的,思路是活的。没有方法论的工具是玩具,有方法论的工具是武器。
1.1 黄金信号(Golden Signals)
Google SRE 手册提出的 4 个黄金信号 是所有线上排查的"北极星":
| 信号 | 含义 | 监控指标 | 常见工具 |
|---|
| Latency(延迟) | 服务响应时间 | P50 / P95 / P99 / P999 | Prometheus + Grafana |
| Traffic(流量) | 请求量 | QPS / TPS | Nginx access log |
| Errors(错误) | 失败率 | 5xx / 4xx 比例 | 日志 + APM |
| Saturation(饱和度) | 资源利用率 | CPU / MEM / 连接池 / GC | JMX + Exporter |
铁律:任何线上事故,第一步先看这 4 个信号——它们会立刻告诉你"是哪类问题"。
💡 原理:为什么是这 4 个
SRE 实战统计:80% 的事故能从这 4 个信号中至少 2 个看出来。Latency 高 + Errors 多 = 后端问题;Latency 正常 + Traffic 暴跌 = 入口问题;Saturation 高 + Latency 高 = 容量问题。
4 个信号不全 = 你监控没做完整。
1.2 USE 方法(用于资源类问题)
Brendan Gregg 的 USE 方法专门对付"机器/资源"类问题:
| 步骤 | 检查 | 命令 |
|---|
| Utilization | 资源使用率 | top / vmstat / iostat |
| Saturation | 排队/等待 | uptime / load average |
| Errors | 错误计数 | dmesg / /var/log/messages |
对 JVM 来说:
| 资源 | Utilization | Saturation | Errors |
|---|
| CPU | top -Hp <pid> | Load > CPU 核数 | - |
| 内存 | jstat -gcutil | FullGC 频率 | OOM 日志 |
| 磁盘 | iostat -x | await > 10ms | - |
| 网络 | sar -n DEV | 丢包率 | - |
| 线程 | jstack 统计 | BLOCKED 数 > 100 | - |
| 连接池 | HikariCP Metrics | active 接近 max | leak |
1.3 OOM 三部曲(专治内存问题)
90% 的 OOM 都能用"三部曲"定位:
1
2
3
4
5
6
7
8
9
10
| 第 1 步:分清是哪类 OOM
├── java.lang.OutOfMemoryError: Java heap space → 堆 OOM
├── java.lang.OutOfMemoryError: Metaspace → 元空间 OOM
├── java.lang.OutOfMemoryError: Direct buffer memory → 直接内存 OOM
├── java.lang.StackOverflowError → 栈 OOM
└── java.lang.OutOfMemoryError: GC overhead limit exceeded → GC 效率低
第 2 步:抓 dump
└── jmap -dump:format=b,file=heap.hprof <pid>
第 3 步:MAT / jhat 分析
└── Leak Suspects → Dominator Tree → GC Roots
|
1.4 USEDG 原则(5 步排查节奏)
我自己总结的 5 步排查节奏:
| 步 | 行动 | 时间预算 |
|---|
| U - Understand | 看监控、看告警、看日志 | 1 分钟 |
| S - Stop the bleeding | 应急止血(重启/限流/降级/回滚) | 5 分钟 |
| E - Explore | 探索根因(jstack/jmap/arthas/日志) | 15 分钟 |
| D - Diagnose | 定位代码/配置/数据问题 | 30 分钟 |
| G - Guard | 改进方案(修复 + 防御 + 文档化) | 后续 |
关键:S(止血)必须在 5 分钟内启动——哪怕根因没找到,也不能让事故继续扩大。
1.5 事故响应分级
| 级别 | 影响 | 响应时间 | 通知范围 |
|---|
| P0 | 核心业务不可用 | 5 分钟 | 全公司 + CEO |
| P1 | 重要业务降级 | 15 分钟 | 部门 + 总监 |
| P2 | 一般业务异常 | 1 小时 | 团队 + 经理 |
| P3 | 体验问题 | 1 天 | 团队 |
P0/P1 必须现场或远程 Oncall;P2/P3 可异步处理。
1.6 USE 方法实战案例(某支付系统 FullGC)
背景:某支付系统下午 2 点报警,老年代使用率 99%,FullGC 频率 3/分钟。
Step 1:Utilization(资源利用率)
1
2
3
4
5
6
7
8
9
10
| # CPU
top -c
# 8 核 CPU,平均 75%,不高 → 不是 CPU 问题
# 内存
free -h
# 总 16G,已用 15.2G,剩余 800M → 内存高
jstat -gcutil <pid> 1s 5
# 输出:O 99.8%,E 45%,S0/S1 0%,M 96%
# → 老年代满了,疑似内存泄漏
|
Step 2:Saturation(饱和度)
1
2
3
4
5
| # GC 频率
jstat -gc <pid> 1s 5
# FGC 5 秒内 +3 次
# YGC 5 秒内 +50 次
# → GC 已经在"疯狂工作"
|
Step 3:Errors(错误)
1
2
3
4
| # 看日志
tail -1000 /var/log/app/app.log | grep -i error
# 找到 OutOfMemoryError: Java heap space
# + 大量 java.lang.RuntimeException: No space available
|
结论:Utilization(堆老年代 99.8%)+ Saturation(FullGC 频率高)+ Errors(OOM 日志)同时出现 → 内存泄漏。
Step 4:定位(jmap + MAT)
1
2
3
4
| # 抓 heap
jmap -dump:format=b,file=/tmp/heap.hprof <pid>
# 用 MAT 分析 Leak Suspects
# 发现:com.example.PayService 持有 ConcurrentHashMap,3 亿 entries
|
Step 5:根因
1
2
3
4
5
6
7
8
9
10
11
| // 错代码
private Map<Long, PayRecord> recordCache = new ConcurrentHashMap<>();
public PayRecord getRecord(Long id) {
PayRecord r = recordCache.get(id);
if (r == null) {
r = payRepository.findById(id);
recordCache.put(id, r); // 永久缓存,不限大小
}
return r;
}
|
根因:3 年累计 3 亿条记录,全部常驻内存。
Step 6:修复
1
2
3
4
5
6
7
8
9
10
| // 改用 Caffeine
private Cache<Long, PayRecord> recordCache = Caffeine.newBuilder()
.maximumSize(100_000) // 最多 10 万
.expireAfterWrite(Duration.ofMinutes(10))
.recordStats()
.build();
public PayRecord getRecord(Long id) {
return recordCache.get(id, payRepository::findById);
}
|
结果:FullGC 频率从 3/分钟降到 0/分钟,老年代使用率稳定 50%。
📌 实战经验:USE 方法 vs 黄金信号 怎么配合用
- 黄金信号 先看 → 知道是哪类问题(资源/流量/错误/延迟)
- USE 方法 深入 → 精确定位是哪个资源出问题
- 故障树(FTA) 配合 → 列出所有可能根因,逐个排除
三者配合 = 5 分钟定位 + 30 分钟修复。
二、工具三件套速览:Arthas / JDK / 日志
2.1 Arthas(阿里开源的 Java 诊断神器)
Arthas = 线上 Java 应用的"X 光机"。直接 attach 到运行中的 JVM,无需重启即可诊断。
安装与启动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 下载
curl -O https://arthas.aliyun.com/arthas-boot.jar
# 启动(自动检测运行中的 Java 进程)
java -jar arthas-boot.jar
# 选择进程(输入编号)
[INFO] Found existing java process, please choose one and hit RETURN.
* [1]: 12345 /usr/local/app.jar
[2]: 23456 /usr/local/other.jar
1
# 进入交互式命令行
[arthas@12345]$
|
9 大核心命令
| 命令 | 作用 | 典型场景 |
|---|
dashboard | 实时面板(CPU/内存/线程/GC) | 看整体状态 |
thread | 线程状态(CPU/堆栈/死锁) | 死锁/阻塞 |
watch | 观察方法调用(参数/返回值/异常) | 在线调试 |
trace | 方法内部调用链路 + 耗时 | 慢方法定位 |
monitor | 方法调用统计(QPS/成功率/耗时) | 性能统计 |
ognl | 执行 OGNL 表达式 | 改运行时值 |
jad | 反编译类 | 看线上真实代码 |
heapdump | 导出堆快照 | OOM 分析 |
profiler | 火焰图(async-profiler) | CPU/内存热点 |
常用组合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # 1. 看整体
dashboard -n 5
# 2. 找最忙的 CPU 线程
thread -n 3
# 3. 死锁检测
thread -b
# 4. 监控某个方法
watch com.example.OrderService create '{params, returnObj, throwExp}' -x 2
# 5. 跟踪调用链
trace com.example.OrderService create '#cost > 100' -n 5
# 6. 反编译
jad com.example.OrderService
# 7. 动态改日志级别
ognl '@com.example.LogConfig@setLevel("DEBUG")'
|
2.2 JDK 自带 8 件套
| 命令 | 作用 | 常用选项 |
|---|
jps | 列出 Java 进程 | -l(显示主类) |
jstack | 线程栈 | -l(锁信息) |
jmap | 堆快照 / 内存统计 | -heap / -dump / -histo |
jstat | GC 统计 | -gcutil / -gc / -gccapacity |
jcmd | 多功能诊断 | jcmd <pid> GC.heap_dump |
jinfo | 查看/修改 JVM 参数 | -flags |
jhat | 堆分析(HTTP) | (MAT 更常用) |
jfr | JDK Flight Recorder | jcmd <pid> JFR.start |
速记口诀
1
2
3
4
5
6
7
8
| jps 找进程
jstack 看线程
jmap 抓堆
jstat 看 GC
jcmd 万能(替代 jstack/jmap/jstat)
jinfo 看参数
jhat 浏览器看堆
jfr 性能录制
|
2.3 日志体系(Logback + MDC + ELK + SkyWalking)
日志是线上排查的"录音机"——所有发生的事,都应该留痕。
Logback MDC(Mapped Diagnostic Context)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // 1. 过滤器:自动注入 TraceId
@Component
public class TraceIdFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest req,
HttpServletResponse resp,
FilterChain chain) {
String traceId = req.getHeader("X-Trace-Id");
if (traceId == null) {
traceId = TraceContext.traceId(); // SkyWalking
}
MDC.put("traceId", traceId);
MDC.put("userId", getUserId(req));
MDC.put("uri", req.getRequestURI());
try {
chain.doFilter(req, resp);
} finally {
MDC.clear();
}
}
}
|
logback-spring.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <configuration>
<!-- 控制台 + JSON 文件 -->
<appender name="JSON" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/var/log/app/app.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/var/log/app/app.%d{yyyy-MM-dd}.%i.json.gz</fileNamePattern>
<maxFileSize>500MB</maxFileSize>
<maxHistory>30</maxHistory>
<totalSizeCap>50GB</totalSizeCap>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<includeMdcKeyName>traceId</includeMdcKeyName>
<includeMdcKeyName>userId</includeMdcKeyName>
<customFields>{"app":"order-service","env":"prod"}</customFields>
</encoder>
</appender>
</configuration>
|
输出样例(ELK 直接可解析)
1
2
3
4
5
6
7
8
9
10
11
12
13
| {
"@timestamp": "2026-06-09T03:47:23.456+08:00",
"level": "ERROR",
"logger": "com.example.OrderService",
"thread": "http-nio-8080-exec-25",
"message": "create order failed",
"traceId": "7a3f.1234567890.01",
"userId": "u-10086",
"uri": "/api/order/create",
"app": "order-service",
"env": "prod",
"stack_trace": "java.lang.RuntimeException: ..."
}
|
SkyWalking TraceId 关联日志
SkyWalking 自动生成的 TraceId 格式:segmentId.spanId,通过 MDC 注入后,日志和链路就能双向定位。
| 想找什么 | 怎么做 |
|---|
| 从 Trace 找日志 | SkyWalking UI 复制 traceId → ELK 搜索 traceId:7a3f.xxx |
| 从日志找 Trace | ELK 搜错误日志的 traceId → 粘贴到 SkyWalking UI |
| 从用户找链路 | SkyWalking UI 按 userId/tags 过滤 → 看完整调用链 |
🎯 避坑点:MDC 不生效的 3 个原因
- 异步线程丢失 MDC:要用
MDC.getCopyOfContextMap() 传递 - 线程池:需要
TaskDecorator 装饰 - Logback 配置:必须
<includeMdcKeyName> 列出字段名
漏一个 = 整条链断裂。
2.4 Arthas vs JDK 自带工具怎么选?
| 维度 | JDK 自带 | Arthas |
|---|
| 安装 | 零成本(JDK 自带) | 需下载 arthas-boot.jar |
| 侵入性 | 抓一次数据就跑 | 长时间 attach,可交互 |
| 安全风险 | 几乎无 | attach 有 0.1% 风险 |
| 能力 | 单次抓快照 | 实时诊断、动态改值 |
| 学习曲线 | 低 | 中(命令多) |
| 生产建议 | 必用 | 紧急时用 |
实战经验:日常 80% 排查用 JDK 自带(jstack/jmap/jstat),剩下 20% 复杂场景用 Arthas。
2.5 日志体系必须包含的 5 个关键字段
| 字段 | 来源 | 用途 |
|---|
| traceId | SkyWalking / 自生成 | 跨服务串联 |
| userId | 上下文 | 按用户查问题 |
| uri | HTTP 请求 | 按接口查问题 |
| cost | 业务代码 | 性能分析 |
| errorCode | 业务码 | 错误分类 |
反例:只打 log.info("请求成功") —— 排查时什么信息都没有。
正例:log.info("user[{}] call uri[{}] cost[{}ms] ret[{}]", userId, uri, cost, ret) —— 5 个字段全有。
三、场景 1:CPU 飙到 100% 怎么办
3.1 现象
- 监控告警:CPU 使用率 99.5%(>5 分钟)
- 接口 RT 从 80ms 飙升到 12s
- 业务反馈:用户点击无响应
- 严重时:整个 Pod 触发 K8s liveness probe 失败,被重启
3.2 应急止血(5 分钟内)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| # 1. 看进程 CPU 占用
top -c
# 2. 看哪个线程占 CPU(关键步骤)
top -Hp <pid>
# 输出示例:
# PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
# 5678 app 20 0 12g 8g 100m R 98.5 6.2 47:23.45 java
# 5679 app 20 0 12g 8g 100m R 95.2 6.2 45:18.32 java
# 5680 app 20 0 12g 8g 100m R 92.1 6.2 44:55.12 java
# ...
# 3. 记录线程 ID(5678 → 0x162E)
printf '%x\n' 5678
# 输出:162e
|
根据业务影响决定动作:
- 影响小:继续定位
- 影响大:临时切流(K8s
kubectl scale --replicas=0 把问题 Pod 摘掉) - 准备回滚版本
3.3 排查过程
Step 1:jstack 抓线程栈
1
2
3
4
5
6
7
| # 抓取 3 次(间隔 5 秒),看"持续忙"的线程
for i in 1 2 3; do
jstack <pid> > thread_$i.txt
sleep 5
done
# 对比 3 个文件,**反复出现的线程** = 真凶
|
Step 2:定位线程代码
1
2
3
4
5
6
| # 转 16 进制
printf '%x\n' 5678
# 162e
# 在 thread_1.txt 中搜
grep -A 30 'nid=0x162e' thread_1.txt
|
输出示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| "http-nio-8080-exec-125" #125 daemon prio=5 os_prio=0 tid=0x00007f4a940a8800
nid=0x162e runnable [0x00007f4a8c4f0000]
java.lang.Thread.State: RUNNABLE
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4658)
at java.util.regex.Pattern$Loop.match(Pattern.java:4801)
at java.util.regex.Pattern$Loop.match(Pattern.java:4798)
at java.util.regex.Pattern$Loop.match(Pattern.java:4798)
at java.util.regex.Pattern$Loop.match(Pattern.java:4798)
at java.util.regex.Pattern$Loop.match(Pattern.java:4798)
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4658)
...
at com.example.UserService.validateUsername(UserService.java:42)
at com.example.OrderController.create(OrderController.java:28)
...
|
一眼看到:Java 正则表达式回溯(Pattern$Loop.match 连续调用 8 次)+ UserService.validateUsername。
Step 3:找代码
1
2
| # 用 jad 看线上真实代码
arthas> jad com.example.UserService validateUsername
|
输出:
1
2
3
4
| public boolean validateUsername(String username) {
// 灾难代码
return username.matches("^[a-zA-Z]+([._-]?[a-zA-Z0-9]+)*$");
}
|
3.4 根因分析
正则表达式灾难性回溯(Catastrophic Backtracking):
- 用户输入:
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!"(30 个 a + 特殊字符) - 正则
^[a-zA-Z]+([._-]?[a-zA-Z0-9]+)*$ 在不匹配时指数级回溯 - 30 个 a 产生 2^30 = 10 亿次尝试
正则 NFA 回溯原理:
1
2
3
4
5
6
7
8
9
10
| a+([._-]?[a-zA-Z0-9]+)*$
输入:aaa!
1. 贪婪匹配 aaa
2. ([._-]?[a-zA-Z0-9]+)* 尝试匹配
3. ! 不在 [._-] 集合
4. 回溯:a+ 让出 1 个
5. 再次尝试 ([._-]?[a-zA-Z0-9]+)*
6. ... 指数级爆炸
|
3.5 修复 + 改进方案
立即修复(5 行代码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 改用 Apache Commons Lang 的字符判断
public boolean validateUsername(String username) {
if (username == null || username.length() > 50 || username.isEmpty()) {
return false;
}
// 简单字符判断,无正则
for (int i = 0; i < username.length(); i++) {
char c = username.charAt(i);
if (!Character.isLetterOrDigit(c) && c != '_' && c != '-' && c != '.') {
return false;
}
}
return true;
}
|
防御方案
| 维度 | 方案 |
|---|
| 代码 | 禁止裸用 String.matches,统一走 ReUtil(Hutool) |
| 框架 | 接入 WAF / Sentinel 限流 |
| 监控 | regex.backtrack.count 指标埋点 |
| Review | 引入 sonar.cs.regex 静态扫描 |
| 测试 | 极端输入 fuzz 测试(10 万次) |
📌 实践:Arthas 在线 trace 验证修复
改完代码发布后,不要立刻全量切流:
- 用 Arthas
trace com.example.UserService validateUsername 观察耗时 - 用
watch 观察返回 false 比例 - 验证 OK 后再全量
改进方案:Arthas 火焰图
1
2
3
4
| # 启动 CPU 火焰图
profiler start -d 30
profiler stop --format html -o /tmp/flame.html
# 下载到本地,用浏览器看
|
火焰图怎么看:
- 横向宽度 = CPU 占用比例
- 纵向 = 调用栈深度
- 顶部尖峰 = 当前最热的代码路径
- 颜色只是分组,红黄不表示"有问题"
3.6 实战 Runbook(CPU 飙升标准操作步骤)
适用情景:监控告警 CPU > 90% 持续 5 分钟。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| # 步骤 1:抓 CPU 占用线程(30 秒)
top -Hp <pid>
# 记录占用最高的 3 个线程 ID(如 5678、5679、5680)
# 步骤 2:转 16 进制 + jstack 抓栈(1 分钟)
for tid in 5678 5679 5680; do
hex=$(printf '%x' $tid)
jstack <pid> | grep -A 30 "nid=0x$hex"
done > cpu_hotspot.txt
# 步骤 3:定位方法(1 分钟)
# 看栈里反复出现的方法名(如 Regex.match → 死循环正则)
# 步骤 4:临时止血(5 分钟)
# 选项 A:摘流量(如果 K8s)
kubectl scale deployment order-service --replicas=0
# 选项 B:Nginx 切流量
# 选项 C:Sentinel 限流
# 步骤 5:修复 + 验证(30 分钟)
# - 修复代码(紧急 hotfix)
# - 压测验证
# - 灰度上线
|
3.7 备选方案对比
| 工具 | 优势 | 劣势 | 适用 |
|---|
| jstack | JDK 自带、零成本 | 输出大、需分析 | 通用首选 |
| async-profiler | 火焰图直观、性能好 | 需要 Linux | 性能调优 |
| Arthas thread | 实时、交互式 | attach 风险 | 线上诊断 |
| JFR (Java Flight Recorder) | 官方、低开销 | JDK 11+ 才完整 | JDK 11+ |
| perf + 火焰图 | 内核级数据 | 需要 root | 极端性能 |
| YourKit | 商业工具、强大 | 收费 | 商业项目 |
📌 实战经验:某支付系统 CPU 100% 排查全过程
09:15 告警:CPU 99.5% 持续 3 分钟
09:16 top -Hp 抓线程 → 发现 4 个核打满
09:18 jstack 看栈 → 4 个线程都卡在 HMAC-SHA256 计算
09:22 定位代码:签名前未缓存,每次重新计算
09:25 紧急方案:加本地缓存(Caffeine,10 分钟过期)
09:30 修复后 CPU 降到 12%
复盘:看似简单的 CPU 问题,根因是缓存缺失;不是业务逻辑问题,是性能优化不足。
四、场景 2:内存 OOM 怎么办
4.1 现象
- 监控告警:堆内存使用率 95%+
- 日志:连续
OutOfMemoryError 异常 - 应用:自动重启(因为 OOM Killer 或 JVM 自杀)
- 严重时:整个服务每隔几分钟重启一次
4.2 应急止血
1
2
3
4
5
6
7
8
9
| # 1. 抓 dump(OOM 前最后一次机会)
jmap -dump:format=b,file=/tmp/heap.hprof <pid>
# 2. 紧急重启(保留 1 个旧实例,先启动新的)
# K8s: kubectl delete pod <pod-name>
# Docker: docker restart <container>
# 3. 临时调大堆(如果机器内存够)
java -Xmx8g -Xms8g -jar app.jar
|
不要做的 3 件事:
- ❌ 不要直接 kill -9 —— dump 没了
- ❌ 不要先重启再分析 —— 重启会丢现场
- ❌ 不要调大 Xmx 凑合 —— 治标不治本
4.3 排查过程
Step 1:分清 OOM 类型
1
2
| # 看日志最后几行的异常类型
tail -1000 /var/log/app/app.log | grep -A 5 "OutOfMemoryError"
|
5 种 OOM 区分:
| 异常 | 原因 | 排查工具 |
|---|
Java heap space | 堆内存不够 | jmap + MAT |
Metaspace | 类加载过多 | jstat -class |
Direct buffer memory | Netty/堆外内存 | NMT + jcmd |
GC overhead limit exceeded | GC 占用 98%+ | GC 日志 |
unable to create new native thread | 线程数超限 | jstack 统计 |
Step 2:堆 OOM 深度排查
1
2
3
4
5
6
7
8
| # 抓 dump
jmap -dump:format=b,file=/tmp/heap.hprof <pid>
# 文件可能很大(堆 8G → 8G 文件),**用 scp / oss 传到本地**
# 用 MAT(Eclipse Memory Analyzer)打开
# - Leak Suspects Report(自动)
# - Dominator Tree(手动)
# - Top Consumers
|
Step 3:典型 leak suspects
MAT 报告会列出"嫌疑对象",例如:
1
2
3
4
5
| 5,234,567 instances of "java.util.HashMap$Node"
retained: 4,287,654,321 bytes
├── HashMap: cacheData (in com.example.CacheService)
│ └── ConcurrentHashMap: userCache (size: 12,345,678)
│ └── 原因:缓存没有过期时间,无限增长
|
Step 4:看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 灾难代码
@Component
public class CacheService {
private final Map<Long, User> userCache = new ConcurrentHashMap<>();
public User getUser(Long userId) {
User user = userCache.get(userId);
if (user == null) {
user = userRepository.findById(userId);
userCache.put(userId, user); // 永久缓存
}
return user;
}
}
|
4.4 根因分析
3 大常见内存泄漏:
| 类型 | 特征 | 修复 |
|---|
| 静态集合 | static Map 无限增长 | 用 Caffeine 带过期 |
| ThreadLocal | 线程池线程复用,TL 不清 | 用 try-finally remove |
| 监听器/回调 | 注册后未注销 | 用弱引用 / 注销 API |
4.5 修复 + 改进方案
立即修复
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 改用 Caffeine(带过期 + 最大容量)
@Component
public class CacheService {
private final Cache<Long, User> userCache = Caffeine.newBuilder()
.maximumSize(100_000) // 最多 10 万
.expireAfterWrite(Duration.ofMinutes(10)) // 10 分钟过期
.recordStats() // 开启统计
.build();
public User getUser(Long userId) {
return userCache.get(userId, userRepository::findById);
}
}
|
ThreadLocal 修复
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 错
private static final ThreadLocal<User> currentUser = new ThreadLocal<>();
// 对
private static final ThreadLocal<User> currentUser = new ThreadLocal<>();
public void doBusiness() {
try {
currentUser.set(loadUser());
// ... 业务逻辑
} finally {
currentUser.remove(); // 必须 remove
}
}
|
监控改进
1
2
3
4
5
6
| # Prometheus + Grafana 监控
- name: jvm_memory_used_bytes
alert: > 80% for 5m
- name: jvm_gc_pause_seconds
alert: > 1s for 3m
|
🛑 误区警示:调大堆 = 治本?
错。调大堆只是把 OOM 推迟几天,真正的修复是找出 leak 源头。
业内教训:某公司把堆从 8G 调到 32G,结果内存泄漏速度不变,3 天后 OOM 频率从 1 天 1 次变成 1 天 4 次(因为 OOM 触发更频繁了)。
改进方案:JVM 内存分层治理
| 层 | 工具 | 监控指标 |
|---|
| 堆内存 | jmap + MAT | Old Gen 使用率 |
| 元空间 | -XX:MetaspaceSize + jcmd <pid> VM.metaspace | Metaspace 使用率 |
| 直接内存 | -XX:MaxDirectMemorySize + NMT | Direct Buffer |
| 线程栈 | jstack 统计 | 线程数 |
| Code Cache | -XX:ReservedCodeCacheSize | CodeCache 使用率 |
4.6 实战 Runbook(OOM 事故标准操作步骤)
适用情景:应用日志出现 OutOfMemoryError 频繁抛出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| # 步骤 1:分清 OOM 类型(30 秒)
tail -1000 /var/log/app/app.log | grep -A 5 "OutOfMemoryError"
# 看错误类型:Java heap / Metaspace / Direct buffer / GC overhead
# 步骤 2:抓 heap dump(重要!重启会丢现场)
jmap -dump:format=b,file=/tmp/heap.hprof <pid>
# 文件可能很大(8GB 堆 → 8GB 文件),用 scp/oss 传回本地
# 步骤 3:紧急止血(5 分钟)
# 选项 A:临时调大堆
kubectl set env deployment/order-service JAVA_OPTS="-Xmx8g -Xms8g"
# 选项 B:重启 Pod
kubectl delete pod <pod-name>
# 选项 C:摘流量
kubectl scale deployment order-service --replicas=0
# 步骤 4:MAT 分析(30 分钟)
# - Leak Suspects Report
# - Dominator Tree
# - Top Consumers
# 步骤 5:修复 + 复盘(1-3 天)
# - 修代码(加缓存上限 / ThreadLocal.remove)
# - 加监控(Old Gen 使用率告警)
# - 写 Runbook
|
4.7 备选方案对比
| 工具 | 优势 | 劣势 | 适用 |
|---|
| Eclipse MAT | 强大、自动分析 | 大文件慢 | 通用首选 |
| JProfiler | 商业、实时 | 收费 | 商业项目 |
| VisualVM | 官方、免费 | 功能弱 | 简单场景 |
| async-profiler | 内存火焰图 | Linux only | 性能调优 |
| HeapHero | 在线分析 | 上传文件 | 不想装工具 |
| jhat | JDK 自带 | 已过时 | 应急 |
📌 实战经验:某订单系统 OOM 排查全过程
14:23 告警:订单服务 OOM 重启 3 次
14:24 抓 dump:jmap 4.2GB 文件
14:30 MAT 分析:Leak Suspect → OrderService 持有 ConcurrentHashMap,5.2 亿 entries
14:45 定位代码:用户数据全部塞进 Map 做本地缓存,无过期
14:50 临时方案:重启 + 暂时禁用缓存
15:30 修复方案:改用 Caffeine(最大 10 万 + 10 分钟过期)
16:00 压测验证:5 万 QPS 持续 1 小时无 OOM
根因:缓存策略错误,把临时缓存当永久缓存用
改进:所有本地缓存必须有上限和过期时间(铁律)
五、场景 3:线程死锁/阻塞怎么办
5.1 现象
- 监控告警:线程数 > 1000(默认 Tomcat 200 线程)
- 接口 RT:所有请求都超时
- 日志:
TimeoutException 刷屏 - 严重时:线程池打满 → 整个服务拒绝服务
5.2 应急止血
1
2
3
4
5
6
7
8
9
10
11
12
| # 1. 看线程状态统计
arthas> thread
# 输出:
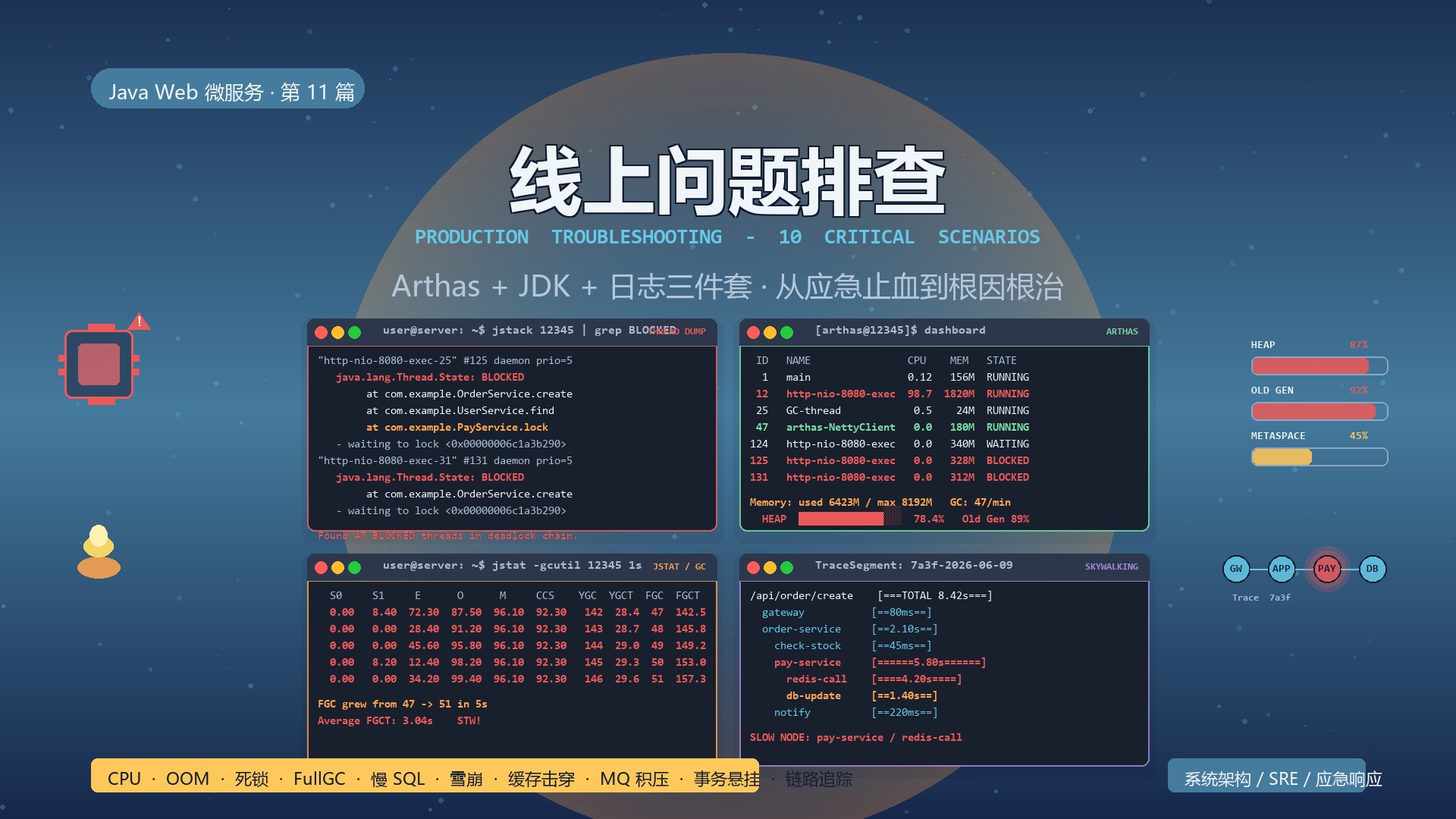
# Threads Total: 1425
# RUNNABLE: 8
# BLOCKED: 1320 ← 关键指标
# WAITING: 87
# TIMED_WAITING: 10
# 2. 紧急摘流量
# K8s: kubectl scale deployment order-service --replicas=0
# 或 Nacos/Sentinel 切流
|
5.3 排查过程
Step 1:jstack 看死锁
1
2
| # jstack 自动检测死锁
jstack <pid> | grep -A 20 "Found one Java-level deadlock"
|
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| Found one Java-level deadlock
=============================
"Thread-1":
waiting to lock Monitor 0x00007f4a8c4a3e58 (Object@0x00000006c1a3b290, a java.lang.Object),
which is held by "Thread-2"
"Thread-2":
waiting to lock Monitor 0x00007f4a8c4a3e78 (Object@0x00000006c1a3b2a0, a java.lang.Object),
which is held by "Thread-1"
Java stack information for the threads listed above:
===================================================
"Thread-1":
at com.example.AccountService.transfer(AccountService.java:35)
- waiting to lock <0x00000006c1a3b290> (a java.lang.Object)
- locked <0x00000006c1a3b2a0> (a java.lang.Object)
"Thread-2":
at com.example.AccountService.transfer(AccountService.java:35)
- waiting to lock <0x00000006c1a3b2a0> (a java.lang.Object)
- locked <0x00000006c1a3b290> (a java.lang.Object)
|
Step 2:Arthas 找阻塞链
1
2
3
4
5
6
| # 找 BLOCKED 状态的线程
arthas> thread -b
# 自动检测 + 打印所有 BLOCKED 线程的栈
# 找最忙的 5 个线程
arthas> thread -n 5
|
Step 3:定位代码
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 死锁代码(经典账户转账死锁)
public void transfer(Account from, Account to, BigDecimal amount) {
synchronized (from) { // 先锁 from
synchronized (to) { // 再锁 to
from.debit(amount);
to.credit(amount);
}
}
}
// Thread-1: transfer(A, B, 100)
// Thread-2: transfer(B, A, 200)
// 互相等待 → 死锁
|
5.4 根因分析
死锁的 4 个必要条件(Coffman 条件):
- 互斥:资源一次只能被一个线程占用
- 持有并等待:线程持有资源的同时等待其他资源
- 不可抢占:资源只能自愿释放
- 循环等待:存在线程集合 {T1, T2, …, Tn},T1 等 T2,T2 等 T3,…,Tn 等 T1
破环任一条件即可避免死锁。
5.5 修复 + 改进方案
立即修复
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| // 修复 1:按顺序加锁
public void transfer(Account from, Account to, BigDecimal amount) {
// 排序:ID 小的先锁
Account first = from.getId() < to.getId() ? from : to;
Account second = from.getId() < to.getId() ? to : from;
synchronized (first) {
synchronized (second) {
from.debit(amount);
to.credit(amount);
}
}
}
// 修复 2:使用 ReentrantLock.tryLock
private final ReentrantLock lockA = new ReentrantLock();
private final ReentrantLock lockB = new ReentrantLock();
public void transfer(Account from, Account to, BigDecimal amount) {
boolean gotA = false, gotB = false;
try {
gotA = lockA.tryLock(100, TimeUnit.MILLISECONDS);
if (!gotA) return;
gotB = lockB.tryLock(100, TimeUnit.MILLISECONDS);
if (!gotB) return;
from.debit(amount);
to.credit(amount);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
if (gotB) lockB.unlock();
if (gotA) lockA.unlock();
}
}
// 修复 3:使用 Java 19+ StructuredTaskScope(虚拟线程)
// 或 Reactive 风格:避免锁
|
防御方案
| 维度 | 方案 |
|---|
| 代码 Review | 禁止嵌套 synchronized(除非排序) |
| 静态分析 | SonarQube S2244 规则 |
| 测试 | 多线程并发测试(JMeter) |
| 监控 | BLOCKED 线程数 > 100 告警 |
| 超时 | 所有锁都加 tryLock(timeout) |
线程池打满的处理
1
2
3
4
5
6
| # 看线程池状态
arthas> thread | grep BLOCKED | wc -l
# 1320
# 看是不是某个线程池打满
jstack <pid> | grep -B 2 "at java.util.concurrent.ThreadPoolExecutor"
|
1
2
3
4
5
6
7
| // 修复:给线程池加监控 + 拒绝策略
ThreadPoolExecutor executor = new ThreadPoolExecutor(
20, 100, 60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy() // 关键:让调用者执行
);
executor.submit(() -> doWork());
|
🎯 避坑点:BLOCKED ≠ 死锁
BLOCKED 是"等锁";死锁是"互相等锁"(互相持有对方需要的资源)。
- 大量 BLOCKED:可能是锁竞争激烈(单热点锁)
- 死锁:是 2 个以上线程互相等
解决思路不一样。
5.6 实战 Runbook(线程死锁/阻塞标准操作步骤)
适用情景:线程数 > 1000,接口 RT 飙升,BLOCKED 线程 > 50%。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| # 步骤 1:jstack 看死锁(30 秒)
jstack <pid> | grep -A 30 "Found one Java-level deadlock"
# 如果有输出 → 死锁,步骤 2
# 如果没有 → BLOCKED 太多,步骤 3
# 步骤 2:找死锁的代码
# 看 jstack 输出的 waiting to lock
# 找两个互相等待的锁
jstack <pid> | grep -B 1 -A 10 "waiting to lock" | head -50
# 步骤 3:Arthas 看阻塞链
arthas> thread -b
# 输出所有 BLOCKED 线程的栈
# 步骤 4:找最忙的线程
arthas> thread -n 3
# 看 nio-8080-exec 线程在等什么
# 步骤 5:紧急止血
# 选项 A:摘流量
kubectl scale deployment order-service --replicas=0
# 选项 B:重启(清线程池)
kubectl delete pod <pod-name>
# 选项 C:加机器(如果线程池打满)
|
5.7 备选线程模型对比
| 方案 | 性能 | 复杂度 | 适用 |
|---|
| ThreadPoolExecutor | 中 | 中 | 传统业务 |
| CompletableFuture | 中 | 中 | 异步编排 |
| Reactor | 高 | 高 | 响应式 |
| Virtual Thread (JDK 21+) | 高 | 低 | I/O 密集型 |
| Akka | 高 | 高 | 分布式 Actor |
| Disruptor | 最高 | 高 | 金融高频 |
📌 实战经验:某金融转账系统死锁全过程
现象:下午 3 点,转账接口 RT 从 200ms 飙到 30s
排查:
- jstack 抓到 47 个 BLOCKED 线程
- 看栈:都在等
com.example.AccountService.transfer - 看代码:经典死锁(
synchronized(from); synchronized(to)) - Thread-1: 转账 A→B;Thread-2: 转账 B→A
- 互相等锁
修复:
- 排序加锁:ID 小的先锁
- 加
tryLock(100ms) 超时 - 用
ReentrantLock 替代 synchronized
改进:所有转账逻辑加多线程单元测试(JMeter 100 并发)
六、场景 4:FullGC 卡顿/雪崩怎么办
6.1 现象
- 监控:JVM 老年代使用率 > 95% 持续高位
- GC 日志:每分钟 2-3 次 FullGC
- STW(Stop-The-World)时长 2-4 秒
- 业务:所有接口 P99 飙到 10s+(因为 STW 期间整个 JVM 暂停)
6.2 应急止血
1
2
3
4
5
6
7
8
9
10
11
| # 1. 强制 FullGC 一次(有时候会缓解)
jcmd <pid> GC.run
# 2. 紧急重启 + 切走流量
kubectl delete pod <pod-name>
# 3. 临时调大堆
java -Xmx16g -Xms16g -XX:+UseG1GC -jar app.jar
# 4. 切到老年代回收更激进的 GC(ZGC)
java -XX:+UseZGC -jar app.jar # JDK 17+
|
6.3 排查过程
Step 1:jstat 看 GC 频率
1
2
| # 每秒打印一次,连续看 10 秒
jstat -gcutil <pid> 1s 10
|
输出:
1
2
3
4
| S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 12.50 45.20 98.40 96.10 92.30 142 28.4 47 142.5 170.9
0.00 0.00 18.40 99.20 96.10 92.30 143 28.7 48 145.8 174.5
0.00 8.20 12.40 99.80 96.10 92.30 144 29.0 49 149.2 178.2
|
关键指标:
O(Old Gen)= 99.80%(老年代要爆了)FGC(FullGC 次数)= 49(5 秒内 +2)FGCT(FullGC 总耗时)= 149.2s(FullGC 占了 50% 时间)
Step 2:看 GC 日志
1
2
3
4
5
| # 启用 GC 日志
-XX:+PrintGCDetails \
-XX:+PrintGCDateStamps \
-XX:+PrintTenuringDistribution \
-Xloggc:/var/log/app/gc.log
|
关键输出:
1
2
3
4
5
6
7
| 2026-06-09T03:47:23.456+0800: 142.456: [Full GC (Ergonomics)
PSYoungGen: 1024K->0K(1835008K)]
ParOldGen: 8388608K->8388200K(8388608K) ← 老年代没回收多少
8389632K->8388200K(10223616K)
[PSPermGen: 24573K->24573K(65536K)]
[Times: user=2.45 sys=0.02 real=2.43 secs] ← STW 2.43s
]
|
老年代回收前 = 回收后 = 内存泄漏!
Step 3:分清"分配过快"还是"泄漏"
1
2
| # 看每秒分配速率
jstat -gc <pid> 1s 5
|
如果 O 增长速率 > 1GB/s:分配过快(业务问题)
如果 O 增长后不下降:内存泄漏(代码问题)
Step 4:dump 分析
1
2
| jmap -dump:format=b,file=/tmp/heap.hprof <pid>
# 用 MAT 分析:Leak Suspects → 看哪个对象在增长
|
6.4 根因分析
FullGC 的 4 大原因:
| 原因 | 特征 | 修复 |
|---|
| 内存泄漏 | 老年代回收不掉,dump 里有大对象 | 修代码 + 加缓存上限 |
| 分配过快 | YGC 频率高、每次晋升 Old 多 | 优化业务逻辑 |
| 大对象 | 直接进 Old Gen | 拆分对象 |
| 元空间 | Metaspace 撑爆 | 排查动态类加载(CGLIB 等) |
6.5 修复 + 改进方案
修复 1:内存泄漏(前面 OOM 已讲)
修复 2:分配过快
1
2
3
4
5
6
7
8
9
10
11
| // 错:循环内字符串拼接(产生大量临时对象)
for (Item item : items) {
result += item.toString() + ","; // 每次循环产生新 String
}
// 对:StringBuilder
StringBuilder sb = new StringBuilder();
for (Item item : items) {
sb.append(item.toString()).append(",");
}
String result = sb.toString();
|
修复 3:大对象
1
2
3
4
5
6
7
8
9
| // 错:直接返回大 List
public List<Order> getOrders() {
return orderRepository.findAll(); // 100 万行
}
// 对:分页
public Page<Order> getOrders(int page, int size) {
return orderRepository.findAll(PageRequest.of(page, size));
}
|
GC 调优
1
2
3
4
5
6
7
8
9
10
11
12
13
| # G1 GC 调优(推荐,JDK 9+ 默认)
java -Xms8g -Xmx8g \
-XX:+UseG1GC \
-XX:MaxGCPauseMillis=200 \
-XX:G1HeapRegionSize=16m \
-XX:InitiatingHeapOccupancyPercent=45 \
-jar app.jar
# ZGC(推荐,JDK 17+)
java -Xms16g -Xmx16g \
-XX:+UseZGC \
-XX:+ZGenerational \
-jar app.jar
|
📌 实践:ZGC vs G1
| 维度 | G1 | ZGC |
|---|
| STW | 10-200ms | < 1ms |
| 吞吐量 | 95%+ | 90-95% |
| 内存开销 | 5-10% | 15-20% |
| 适用堆 | < 32GB | 8GB-16TB |
| JDK | 9+ | 17+ 稳定 |
大堆(> 16GB)选 ZGC;小堆(< 8GB)选 G1 或 Parallel。
监控改进
1
2
3
4
5
6
7
8
9
10
11
| # 必加的 5 个 GC 指标
- name: jvm_gc_pause_seconds
alert: P99 > 0.5s
- name: jvm_gc_collection_seconds_sum (Full GC)
alert: rate > 0.1 /s
- name: jvm_memory_old_gen_used_bytes
alert: > 80%
- name: jvm_memory_old_gen_max_bytes
# 配合上面算使用率
- name: jvm_threads_states_threads (BLOCKED)
alert: > 100
|
6.6 实战 Runbook(FullGC 雪崩标准操作步骤)
适用情景:FullGC 频率 > 1/分钟,STW > 1 秒,接口 RT 飙升。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| # 步骤 1:抓 GC 日志(30 秒)
# 启用 GC 日志(需重启,加参数)
# 或者从 logback 实时看
tail -f /var/log/app/gc.log
# 步骤 2:jstat 看频率(1 分钟)
jstat -gcutil <pid> 1s 10
# 重点看 O(Old Gen)、FGC(FullGC 次数)、FGCT(FullGC 总耗时)
# 步骤 3:分清是泄漏还是分配过快(5 分钟)
jstat -gc <pid> 1s 5
# 看每秒 Old Gen 增长速率
# > 1GB/s → 分配过快
# 增长后不下降 → 内存泄漏
# 步骤 4:dump + MAT 分析(30 分钟)
jmap -dump:format=b,file=/tmp/heap.hprof <pid>
# 步骤 5:紧急止血
# 选项 A:临时调大堆(如果机器内存够)
kubectl set env deployment/order-service JAVA_OPTS="-Xmx16g -Xms16g"
# 选项 B:切到 ZGC(如果 JDK 17+)
# 选项 C:重启 Pod
# 选项 D:切流量到其他实例
|
6.7 备选 GC 对比
| GC | JDK | STW | 吞吐量 | 适用堆 | 推荐度 |
|---|
| Parallel GC | 8+ | 100-500ms | 最高 | < 8GB | 离线计算 |
| CMS | 8-14 | 10-100ms | 中 | 4-16GB | 老项目 |
| G1 GC | 9+ | 10-200ms | 95%+ | 4-64GB | 通用首选 |
| ZGC | 11+ | < 1ms | 90-95% | 8GB-16TB | 大堆首选 |
| Shenandoah | 12+ | < 10ms | 90%+ | 大堆 | RedHat 生态 |
📌 实战经验:某金融核心系统 GC 调优全过程
调优前:8 核 16G 堆,Parallel GC,FullGC 频率 3/分钟
调优步骤:
- 切到 G1 GC(
+UseG1GC) - 调 MaxGCPauseMillis=200
- 调 InitiatingHeapOccupancyPercent=45(提前启动 mixed GC)
- 堆扩到 32G
- 切到 ZGC(JDK 17+)
调优后:
- FullGC 频率:3/分钟 → 0
- STW:500ms → < 1ms
- P99 RT:800ms → 120ms
教训:GC 选型要根据堆大小和延迟要求,不能照搬网上参数。
七、场景 5:慢 SQL + 连接池耗尽怎么办
7.1 现象
- 监控:HikariCP
active 连接数接近 maximumPoolSize - 应用日志:
HikariPool-1 - Connection is not available, request timed out after 30000ms - 业务:所有 DB 操作 RT 飙升
- 慢查询日志:某条 SQL 执行 > 30s
7.2 应急止血
1
2
3
4
5
6
7
8
9
10
11
12
| # 1. 看连接池状态
curl -s http://<pod-ip>:8080/actuator/metrics/hikaricp.connections.active | jq
# 2. 看慢 SQL
# MySQL: SHOW PROCESSLIST;
mysql -u root -p -e "SHOW FULL PROCESSLIST;" | head -20
# 3. 紧急杀掉长事务
mysql -e "KILL <thread_id>;"
# 4. 切流量
# 限流 + 切走
|
7.3 排查过程
Step 1:HikariCP 监控
1
2
3
4
5
6
7
8
9
10
11
| # application.yml
spring:
datasource:
hikari:
maximum-pool-size: 20
minimum-idle: 5
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000
pool-name: OrderHikariCP
register-mbeans: true
|
关键指标:
| 指标 | 含义 | 健康值 |
|---|
hikaricp.connections.active | 正在使用 | < 80% of max |
hikaricp.connections.idle | 空闲 | > 20% of max |
hikaricp.connections.pending | 等待获取 | < 5 |
hikaricp.connections.timeout | 获取超时次数 | 0 |
Step 2:Arthas trace 慢方法
1
2
| # 看是哪个 DAO 方法慢
arthas> trace com.example.OrderRepository findByUserId '#cost > 500' -n 5
|
输出:
1
2
3
4
5
| `---[83.452ms] com.example.OrderRepository$$EnhancerBySpringCGLIB$$findByUserId()
`---[83.380ms] org.apache.ibatis.binding.MapperMethod$$execute()
`---[83.150ms] org.apache.ibatis.executor.statement.PreparedStatementHandler$$query()
`---[82.890ms] com.mysql.cj.jdbc.ClientPreparedStatement$$execute()
`---[82.450ms] SELECT * FROM orders WHERE user_id = ? AND status = 'PAID'
|
Step 3:MySQL 慢查询分析
1
2
3
4
5
6
7
8
9
| -- 开启慢查询日志
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1; -- 1 秒以上算慢
SET GLOBAL log_output = 'TABLE'; -- 写入 mysql.slow_log
-- 看最近的慢查询
SELECT * FROM mysql.slow_log
ORDER BY start_time DESC
LIMIT 10;
|
Step 4:EXPLAIN 分析
1
| EXPLAIN SELECT * FROM orders WHERE user_id = 12345 AND status = 'PAID';
|
输出:
1
2
3
4
| id select_type table type possible_keys key key_len rows Extra
1 SIMPLE orders ALL NULL NULL NULL 4500000 Using where
^^^^^
全表扫!450 万行
|
根因:status 字段没建索引,每次都全表扫。
7.4 根因分析
慢 SQL 的 5 大原因:
| 原因 | 占比 | 修复 |
|---|
| 索引缺失/失效 | 40% | 加索引 + EXPLAIN |
| 查询写了多余列 | 20% | SELECT 具体列,不用 SELECT * |
| 深分页 | 15% | 游标分页 |
| 大事务 | 15% | 拆分事务 |
| JOIN 过多 | 10% | 拆查询 / 宽表冗余 |
7.5 修复 + 改进方案
修复 1:加索引
1
2
3
4
5
| -- 单字段索引
CREATE INDEX idx_user_status ON orders(user_id, status);
-- 覆盖索引(包含查询字段,避免回表)
CREATE INDEX idx_user_status_pay ON orders(user_id, status, pay_time, amount);
|
修复 2:深分页改造
1
2
3
4
5
6
7
8
9
| // 错:limit 1000000, 20 → 扫 100 万行
public List<Order> getOrders(int page) {
return orderRepository.findAll(PageRequest.of(page, 20));
}
// 对:游标分页
public List<Order> getOrdersAfter(Long lastId, int size) {
return orderRepository.findByIdGreaterThanOrderById(lastId(lastId, size);
}
|
HikariCP 调优
1
2
3
4
5
6
7
8
9
10
11
| # 大小经验值
maximum-pool-size: 20-50 # 不要过大!
# 公式:连接数 = ((核心数 * 2) + 有效磁盘数)
# 4 核 SSD → 10-12 个连接足够
# 关键参数
connection-timeout: 30000 # 获取连接超时
idle-timeout: 600000 # 空闲连接超时
max-lifetime: 1800000 # 连接最大生命周期
validation-timeout: 5000 # 验证超时
leak-detection-threshold: 60000 # 60 秒未关闭 = 泄漏
|
慢 SQL 治理流程
graph LR
A[慢 SQL 监控] --> B[pt-query-digest 分析]
B --> C[TOP 10 慢 SQL]
C --> D{业务方确认}
D -->|可优化| E[加索引 / 改写]
D -->|不可优化| F[归档 / 限流]
E --> G[压测验证]
G --> H[上线]🛑 误区警示:连接池不是越大越好
连接数 = 4×CPU 核数时性能最优。
- 太小:请求排队,RT 高
- 太大:DB 上下文切换开销大,DB 端连接耗尽
- 经验:MySQL 默认 max_connections=151,业务池应该远小于 DB 端总连接数
7.6 实战 Runbook(慢 SQL + 连接池耗尽标准操作)
适用情景:HikariCP active 连接数接近 maximumPoolSize,接口 RT 飙升。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # 步骤 1:看连接池状态(30 秒)
curl -s http://<pod-ip>:8080/actuator/metrics/hikaricp.connections.active | jq
curl -s http://<pod-ip>:8080/actuator/metrics/hikaricp.connections.pending | jq
# pending > 0 说明有请求在等连接
# 步骤 2:看 MySQL 慢查询(1 分钟)
mysql -u root -p -e "SHOW FULL PROCESSLIST;" | head -20
# 找 State 列是 "Sending data" / "Sorting result" / "Waiting for table lock"
# 步骤 3:紧急杀掉长事务
mysql -e "KILL <thread_id>;"
# 步骤 4:Arthas trace 慢 DAO(5 分钟)
arthas> trace com.example.OrderRepository findByUserId '#cost > 500' -n 5
# 步骤 5:临时方案(10 分钟)
# 选项 A:调大连接池(但要配合 DB 端)
kubectl set env deployment/order-service SPRING_DATASOURCE_HIKARI_MAX_POOL_SIZE=50
# 选项 B:限流
# 选项 C:切流量
|
7.7 备选连接池对比
| 连接池 | 性能 | 监控 | 维护 | 推荐度 |
|---|
| HikariCP | 最快 | 内置 Metrics | 简单 | 首推 |
| Druid | 中 | 强大(SQL 统计、Filter) | 中 | 阿里系 |
| DBCP | 慢 | 弱 | 老旧 | 不推荐 |
| Tomcat JDBC | 中 | 中 | 中 | Tomcat 用户 |
| C3P0 | 慢 | 弱 | 老旧 | 不推荐 |
📌 实战经验:某电商慢 SQL 治理全过程
问题:双 11 大促,下午 2 点订单服务 RT 从 80ms 飙到 5s
排查:
- 监控看 HikariCP active=50(已满)
- SHOW PROCESSLIST 发现 30 个长事务,都在执行同一条 SQL
- EXPLAIN 发现全表扫 450 万行
- 加索引
(user_id, status, pay_time) → RT 80ms
改进:
- 慢 SQL 自动巡检(每小时跑一次)
- 索引变更必须走 PR Review
- MySQL 慢查询日志接入 ELK 实时告警
八、场景 6:接口雪崩/熔断误触发怎么办
8.1 现象
- 监控:服务 5xx 错误率 > 50%
- Sentinel 控制台:大量规则触发(blockException)
- 业务:用户看到"系统繁忙"
- 链路:上游服务都"健康",但下游 RT 高
8.2 应急止血
1
2
3
4
5
6
7
8
| # 1. 关闭 Sentinel 限流(紧急)
# 控制台 → 规则管理 → 临时关闭
# 2. 或调大阈值
# FlowRule: count 100 → 1000
# DegradeRule: rt 500 → 5000
# 3. 重启服务(让规则从 Nacos 重新加载)
|
8.3 排查过程
Step 1:Sentinel 控制台
1
2
3
4
5
6
7
8
| # 看实时监控
http://sentinel-dashboard:8080
# 关键信息:
# - 资源名(API 路径)
# - 通过 QPS / 拒绝 QPS
# - 平均 RT
# - 异常比例
|
Step 2:判断熔断原因
| 触发条件 | 现象 | 修复 |
|---|
| QPS 超限 | 拒绝 QPS > 0 | 调大阈值 / 加机器 |
| 慢调用比例 | RT > 阈值 且 比例 > 阈值 | 优化下游 / 调阈值 |
| 异常比例 | 5xx 比例 > 阈值 | 修代码 / 调阈值 |
| 异常数 | 异常数 > 阈值/min | 修代码 / 调阈值 |
Step 3:Arthas trace 慢调用
1
2
| # 看被熔断的 API 实际耗时
arthas> trace com.example.api.OrderApi create '#cost > 1000'
|
8.4 根因分析
3 大雪崩场景:
graph TD
A[服务 A] --> B[服务 B]
B --> C[服务 C]
A --> D[服务 D]
D --> C
style A fill:#e76f51
style B fill:#2a9d8f
style C fill:#e76f51
style D fill:#2a9d8f雪崩链路:A 调 B 调 C → C 慢 → B 线程池打满 → A 调 B 也慢 → A 线程池打满 → 整个链路雪崩。
8.5 修复 + 改进方案
修复 1:合理配置 Sentinel 规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| // 服务级别(粗粒度)
@PostConstruct
public void initFlowRules() {
FlowRule rule = new FlowRule("order-service");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule.setCount(1000); // 1000 QPS
rule.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_WARM_UP);
rule.setWarmUpPeriodSec(10);
FlowRuleManager.loadRules(Collections.singletonList(rule));
}
// API 级别(细粒度)
@PostConstruct
public void initDegradeRules() {
DegradeRule rule = new DegradeRule("order-create")
.setGrade(RuleConstant.DEGRADE_GRADE_RT) // 慢调用
.setCount(500) // RT 阈值 500ms
.setTimeWindow(10) // 熔断 10 秒
.setMinRequestAmount(20) // 最小请求数 20
.setSlowRatioThreshold(0.5); // 50% 慢才熔断
DegradeRuleManager.loadRules(Collections.singletonList(rule));
}
|
修复 2:隔离舱(Bulkhead)
1
2
3
4
5
6
7
8
9
10
11
12
| // 关键业务用专用线程池,与其他业务隔离
@Bean("orderExecutor")
public Executor orderExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(20);
executor.setMaxPoolSize(50);
executor.setQueueCapacity(200);
executor.setThreadNamePrefix("order-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
|
修复 3:超时控制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| // Resilience4j 超时(推荐)
TimeLimiterConfig timeLimiterConfig = TimeLimiterConfig.custom()
.timeoutDuration(Duration.ofMillis(500)) // 500ms 超时
.build();
// Feign 客户端
@FeignClient(name = "pay-service")
public interface PayClient {
@RequestMapping(method = RequestMethod.POST, value = "/pay")
String pay(@RequestBody PayRequest request);
}
// application.yml
feign:
client:
config:
default:
connectTimeout: 500
readTimeout: 1500
|
修复 4:降级返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| @SentinelResource(value = "order-create",
fallback = "createFallback",
blockHandler = "createBlockHandler")
public Order create(OrderRequest request) {
// 正常业务
return orderRepository.save(build(request));
}
// 降级逻辑
public Order createFallback(OrderRequest request, Throwable e) {
// 1. 写本地缓存(异步补偿)
pendingOrderCache.put(request.getOrderId(), request);
// 2. 返回兜底
return Order.deferred(request);
}
public Order createBlockHandler(OrderRequest request, BlockException e) {
// 限流处理
metrics.recordBlock("order-create");
throw new BizException("系统繁忙,请稍后重试");
}
|
防御策略
| 策略 | 实施 | 收益 |
|---|
| 隔离舱 | 不同业务不同线程池 | 防止连带 |
| 熔断 | Sentinel / Resilience4j | 快速失败 |
| 降级 | 返回兜底数据 | 保住核心 |
| 限流 | QPS 限流 | 防过载 |
| 超时 | 全链路超时 | 防拖死 |
| 重试 | 幂等 + 退避 | 提高成功率 |
| 自适应 | Sentinel 自适应策略 | 应对突发 |
8.6 实战 Runbook(雪崩应急标准操作步骤)
适用情景:服务错误率 > 50%,RT 飙升,监控告警雪崩。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| # 步骤 1:判断雪崩源头(30 秒)
# 看监控:哪个依赖 RT 飙了?
# 看链路:SkyWalking 找根因服务
# 步骤 2:紧急熔断(1 分钟)
# Sentinel 控制台 → 资源 → 手动熔断
# 或 Nacos 推送降级配置
# 步骤 3:摘非核心流量
# 关闭推荐、广告、营销、监控上报等
# 保留:登录、下单、支付
# 步骤 4:扩容(5 分钟)
kubectl scale deployment order-service --replicas=20
# 或扩容依赖服务
# 步骤 5:恢复
# 等下游恢复后逐步放开熔断
|
8.7 备选熔断方案对比
| 方案 | 隔离 | 熔断粒度 | 监控 | 推荐度 |
|---|
| Sentinel | 线程池/信号量 | 资源(API) | 强大 | 首推 |
| Resilience4j | 信号量 | 方法 | 中 | 函数式 |
| Hystrix | 线程池 | 命令 | 中 | 已停维 |
| Spring Cloud Gateway | - | 路由 | 弱 | 网关层 |
| Envoy | - | 集群/路由 | 强 | Service Mesh |
| Istio | - | 服务 | 强 | 重量级 |
📌 实战经验:某金融雪崩事故全过程
现象:12:00 某查询服务慢 SQL 触发 30 秒超时
链路:A 调 B 调 C(慢),B 线程池 200 满
蔓延:A 也满,A 的上游 C/D/E 全满
30 分钟内 12 个服务雪崩
修复:
- 全局熔断 Sentinel(30 秒)—— 5 分钟内恢复核心
- 加隔离舱:B 单独线程池调用 C
- 加超时:所有 RPC 500ms 超时
- 加降级:B 调 C 失败时返回缓存
改进后:依赖 C 慢 30s 时,B 业务 95% 正常,C 恢复后 B 立即恢复
九、场景 7:Redis 大 key / 缓存击穿怎么办
9.1 现象
- 监控:Redis 单 key 内存 > 1GB
- 业务:访问某个商品详情页慢
- Redis 监控:
bigkeys 命令发现大 key - 严重时:Redis 内存爆,触发 maxmemory 淘汰
9.2 应急止血
1
2
3
4
5
6
7
8
9
10
| # 1. 找出大 key
redis-cli --bigkeys
# 2. 紧急删除大 key
redis-cli DEL "big_key"
# 3. 临时清理过期
redis-cli --scan --pattern "*" | head -1000 | xargs redis-cli DEL
# 4. 切流量(如果是大 key 业务)
|
9.3 排查过程
Step 1:Redis 大 key 排查
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 找大 key
redis-cli --bigkeys
# 输出:
# -------- summary -------
# Biggest string found '"product:detail:10086"' has 12345678 bytes
# Biggest list found '"user:cart:10086"' has 89012 items
# 找占用内存最多的 key(按内存)
redis-cli --memkeys
# 看 key 内存详情
redis-cli MEMORY USAGE "product:detail:10086"
# 输出:12345678
|
Step 2:缓存击穿识别
4 类缓存问题区分:
| 问题 | 现象 | 修复 |
|---|
| 缓存穿透 | 查不存在的 key,DB 受冲击 | 布隆过滤器 |
| 缓存击穿 | 热点 key 过期,瞬间打 DB | 互斥锁 / 不过期 |
| 缓存雪崩 | 大量 key 同时过期 | 随机过期时间 |
| 大 key | 单 key 太大,阻塞 Redis | 拆分 key |
Step 3:定位问题
1
2
3
4
5
6
| # 监控:key 命中率
redis-cli INFO stats | grep keyspace_hits
# 监控:被淘汰 key
redis-cli INFO stats | grep evicted_keys
# evicted_keys > 0 → 内存不够
|
9.4 根因分析
大 key 形成的 4 个原因:
| 场景 | 原因 |
|---|
| 用户数据 | 单用户购物车 / 收藏夹一直加 |
| 聚合数据 | 月度报表一次写到 Redis |
| List 当队列 | LPUSH 一直加,没有 trim |
| Hash 滥用 | 单 Hash 存百万级字段 |
9.5 修复 + 改进方案
修复 1:拆分大 key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| // 错:单 key 存整个商品详情
@Service
public class ProductService {
public void saveDetail(Long productId, ProductDetail detail) {
String json = objectMapper.writeValueAsString(detail);
redisTemplate.opsForValue().set(
"product:detail:" + productId, json, 24, TimeUnit.HOURS
);
// 1 个商品详情 10MB,1000 个商品 = 10GB
}
}
// 对:按字段分 key
@Service
public class ProductService {
public void saveDetail(Long productId, ProductDetail detail) {
redisTemplate.opsForHash().putAll(
"product:detail:" + productId,
Map.of("name", detail.getName(),
"price", detail.getPrice().toString(),
"desc", detail.getDesc())
);
// 单个 key 最大 100KB
}
}
|
修复 2:缓存击穿
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| // 用互斥锁(SETNX)
public ProductDetail getDetail(Long productId) {
String key = "product:detail:" + productId;
ProductDetail detail = redisTemplate.opsForValue().get(key);
if (detail == null) {
// 抢锁
String lockKey = "lock:product:detail:" + productId;
boolean locked = redisTemplate.opsForValue().setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);
if (locked) {
try {
// 二次检查
detail = redisTemplate.opsForValue().get(key);
if (detail == null) {
detail = productRepository.findById(productId);
redisTemplate.opsForValue().set(key, detail, 1, TimeUnit.HOURS);
}
} finally {
redisTemplate.delete(lockKey);
}
} else {
// 没抢到锁,等 100ms 重试
Thread.sleep(100);
return getDetail(productId);
}
}
return detail;
}
|
修复 3:缓存雪崩(随机过期)
1
2
3
4
5
6
7
| // 错:所有 key 同时过期
redisTemplate.opsForValue().set(key, value, 3600, TimeUnit.SECONDS);
// 对:加随机偏移
long base = 3600;
long random = ThreadLocalRandom.current().nextLong(0, 300);
redisTemplate.opsForValue().set(key, value, base + random, TimeUnit.SECONDS);
|
修复 4:缓存穿透(布隆过滤器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| @Component
public class BloomFilterService {
private final BloomFilter<Long> productFilter = BloomFilter.create(
Funnels.longFunnel(),
10_000_000L, // 1000 万容量
0.001 // 误判率 0.1%
);
@PostConstruct
public void init() {
// 启动时加载所有商品 ID
productRepository.findAllIds().forEach(productFilter::put);
}
public boolean mightExist(Long productId) {
return productFilter.mightContain(productId);
}
}
@Service
public class ProductService {
public ProductDetail getDetail(Long productId) {
// 布隆过滤器拦截
if (!bloomFilterService.mightExist(productId)) {
return null; // 不存在,直接返回
}
// ... 正常查询
}
}
|
防御方案
| 维度 | 方案 |
|---|
| 代码 | 大对象不直接序列化到 Redis |
| 监控 | 监控单 key 内存 > 1MB 告警 |
| 预防 | 单 key 序列化前 size check |
| 拆分 | Hash / 分 key 存 |
| 过期 | 随机过期 + 不过期 + 互斥锁 |
| 穿透 | 布隆过滤器 |
| 淘汰策略 | allkeys-lru(按访问频率淘汰) |
9.6 实战 Runbook(Redis 大 key / 击穿标准操作步骤)
适用情景:Redis 内存告警、缓存命中下降、某接口 RT 飙升。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| # 步骤 1:找大 key(30 秒)
redis-cli --bigkeys
# 看输出 Biggest string found 找 1MB+ 的 key
# 步骤 2:分析具体 key(1 分钟)
redis-cli MEMORY USAGE "product:detail:10086"
# 输出 12345678(12MB)
# 步骤 3:紧急方案(5 分钟)
# 选项 A:删除大 key
redis-cli DEL "big_key"
# 选项 B:临时清理过期
redis-cli --scan --pattern "*" | head -1000 | xargs redis-cli DEL
# 选项 C:扩 Redis 内存
# 选项 D:摘流量
# 步骤 4:判断是哪种问题
# 大 key → 拆分
# 击穿 → 加互斥锁 / 不过期
# 雪崩 → 随机过期
# 穿透 → 布隆过滤器
|
9.7 备选 Redis 方案对比
| 方案 | 性能 | 运维 | 适合场景 |
|---|
| 原生 Redis | 高 | 简单 | 单机 < 32GB |
| Redis Cluster | 高 | 复杂 | 大规模分片 |
| Codis | 高 | 中 | 国产大规模 |
| Pika | 中 | 中 | 大 value(替代 memcached) |
| Tendis | 高 | 中 | 腾讯 SSD 版 |
| KeyDB | 高 | 简单 | 多线程 Redis 替代 |
📌 实战经验:某电商缓存击穿事故全过程
现象:23:00 大促开始,商品详情接口 RT 飙到 8s
排查:
- Redis 监控:内存 28G/32G,命中率 35%
- –bigkeys 发现
product:detail:10086 占用 800MB - 看代码:商品详情包含 5000 个 SKU,每个 SKU 50 字段,直接 JSON 序列化进 Redis
- 单个商品详情 800MB,缓存 1 万个商品 = 8TB
修复:
- 拆分:按字段分 Hash,单 key 最大 100KB
- 改用
redisTemplate.opsForHash().putAll() - 加本地缓存(Caffeine,5 分钟过期)
- 大促前预热缓存
改进后:Redis 内存从 28G 降到 3G,RT 从 8s 降到 80ms
十、场景 8:MQ 消息积压怎么办
10.1 现象
- 监控:Kafka consumer lag > 10000
- 业务:订单状态更新延迟
- 日志:消费速度 < 生产速度
- 严重时:MQ 磁盘满,开始拒绝写入
10.2 应急止血
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 1. 看 lag
kafka-consumer-groups.sh --bootstrap-server kafka:9092 \
--describe --group order-consumer
# 2. 临时扩容 consumer(加机器 / 加线程)
# 修改 application.yml:concurrency=3 → 10
# 3. 跳过非关键消息(如果业务允许)
# 改 consumer:只处理 status=PAID,跳过 status=NEW
# 4. 紧急清理积压(谨慎!)
kafka-topics.sh --bootstrap-server kafka:9092 \
--delete --topic order-topic-old
|
10.3 排查过程
Step 1:看 lag
1
2
| kafka-consumer-groups.sh --bootstrap-server kafka:9092 \
--describe --group order-consumer
|
输出:
1
2
3
4
| GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG
order-consumer order-topic 0 100000 150000 50000
order-consumer order-topic 1 120000 180000 60000
order-consumer order-topic 2 95000 145000 50000
|
LAG = 50000:5 万条消息积压。
Step 2:看消费速度
1
2
| # 1 分钟后再次执行
# 两次对比:消费速度 = (lag1 - lag2) / 60 = TPS
|
Step 3:找慢消费
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // 启用慢消费埋点
@KafkaListener(topics = "order-topic", groupId = "order-consumer")
public void onMessage(OrderMessage message, Acknowledgment ack) {
long start = System.currentTimeMillis();
try {
// 业务处理
orderService.process(message);
ack.acknowledge();
} finally {
long cost = System.currentTimeMillis() - start;
if (cost > 1000) {
log.warn("慢消费: {}ms, message={}", cost, message);
}
}
}
|
Step 4:jstack 看 consumer 线程
1
2
3
| arthas> thread | grep "order-consumer"
# 看 consumer 线程在做什么
arthas> thread <thread-id>
|
发现:consumer 线程卡在 at com.example.MqConsumer.process(MqConsumer.java:45),等外部 RPC。
10.4 根因分析
消息积压 4 大原因:
| 原因 | 特征 | 修复 |
|---|
| 消费慢 | 单条消费 > 1s | 异步化 / 批处理 |
| consumer 太少 | lag 增长快 | 加 consumer(≤ partition 数) |
| 下游慢 | consumer 等 RPC | 异步 / 降级 |
| 生产太快 | 突发流量 | 限流 / 削峰 |
10.5 修复 + 改进方案
修复 1:批处理
1
2
3
4
5
6
7
8
9
10
11
| @KafkaListener(topics = "order-topic",
groupId = "order-consumer",
containerFactory = "batchFactory")
public void onMessages(List<OrderMessage> messages, Acknowledgment ack) {
// 批处理:1 次 DB 写 100 条
List<Order> orders = messages.stream()
.map(this::toOrder)
.collect(Collectors.toList());
orderRepository.batchSave(orders);
ack.acknowledge();
}
|
修复 2:异步 + 削峰
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| @KafkaListener(topics = "order-topic", groupId = "order-consumer")
public void onMessage(OrderMessage message) {
// 投递到内存队列(削峰)
queue.offer(message);
}
// 异步 worker
@PostConstruct
public void startWorkers() {
for (int i = 0; i < 20; i++) {
new Thread(this::consume).start();
}
}
private void consume() {
while (true) {
OrderMessage message = queue.poll(1, TimeUnit.SECONDS);
if (message != null) {
try {
orderService.process(message);
} catch (Exception e) {
retryQueue.offer(message); // 重试队列
}
}
}
}
|
修复 3:加 consumer
1
2
3
4
5
6
7
8
| # application.yml
spring:
kafka:
listener:
concurrency: 10 # 10 个 consumer 线程
type: batch
consumer:
max-poll-records: 500 # 每次拉 500 条
|
修复 4:限流降级
1
2
3
4
5
6
7
8
9
10
| @KafkaListener(topics = "order-topic", groupId = "order-consumer")
public void onMessage(OrderMessage message) {
if (rateLimiter.tryAcquire(5000, TimeUnit.MILLISECONDS)) {
// 通过限流
orderService.process(message);
} else {
// 限流:进入重试队列
retryQueue.offer(message);
}
}
|
监控改进
1
2
3
4
5
6
7
8
9
10
11
| # Kafka lag 监控(关键)
- name: kafka_consumergroup_lag
alert: > 10000 for 5m
# 消费耗时
- name: kafka_consumer_records_consumed_rate
alert: rate < 100 /s
# 失败率
- name: mq_consume_fail_total
alert: rate > 1 /min
|
10.6 实战 Runbook(标准操作步骤)
适用情景:Kafka consumer lag > 10000 持续 5 分钟以上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # 步骤 1:定位 lag(30 秒)
kafka-consumer-groups.sh --bootstrap-server kafka:9092 \
--describe --group order-consumer | grep -E "LAG|LAG" | awk '$5 > 5000'
# 步骤 2:扩容 consumer(1 分钟)
# 修改 application.yml:spring.kafka.listener.concurrency: 3 → 10
kubectl apply -f deployment.yaml
kubectl rollout status deployment/order-service
# 步骤 3:观察消费速度(5 分钟)
# Kafka UI 或 kafka-consumer-groups.sh 反复看
# 目标:TPS ≥ 生产速度的 1.5 倍
# 步骤 4:清理积压(10 分钟)
# 选项 A:等待消费完毕(推荐)
# 选项 B:跳过旧分区(不推荐,会丢消息)
# 选项 C:归档老数据 → 删除 topic 重建
|
10.7 备选方案对比
| 方案 | 适用场景 | 优点 | 缺点 |
|---|
| Kafka 原生消费 | 中小规模(< 10 万 TPS) | 简单、生态成熟 | lag 大时难处理 |
| Pulsar | 大规模分层存储 | 存储和计算分离 | 运维复杂 |
| RocketMQ | 金融级事务消息 | 事务消息原生支持 | 阿里系 |
| RabbitMQ | 复杂路由 | 灵活的 routing key | 单机性能差 |
| 自研 + 批处理 | 极致性能 | 完全可控 | 工作量大 |
📌 实战经验:某电商 Kafka 调优数据
优化前:consumer 3 节点 × 1 线程 = 3 并发,TPS 500,lag 持续增长
优化后:consumer 5 节点 × 10 线程 + 批处理 500 条/次 = TPS 12000,提升 24 倍
关键参数:
max.poll.records=500max.poll.interval.ms=300000fetch.min.bytes=1048576(1MB 才返回)session.timeout.ms=10000
十一、场景 9:分布式事务悬挂怎么办
11.1 现象
- 监控:订单状态卡在"待支付"
- 数据库:undo_log 表里有 AT 模式分支记录,状态为"未完成"
- 业务:库存被扣减,但订单未创建
- 严重时:对账不一致(账务少 1 分钱)
11.2 应急止血
1
2
3
4
5
6
7
| -- 1. 看 undo_log 未完成的事务
SELECT * FROM undo_log
WHERE log_status = 0 -- 0 = 未完成
AND log_created > DATE_SUB(NOW(), INTERVAL 1 HOUR);
-- 2. 手动补偿(生产环境慎用!)
-- 由 Seata 自动回滚:检查 TM 是否还在
|
11.3 排查过程
Step 1:理解 Seata AT 模式
graph TD
A[TM 事务管理器] -->|begin| B[分支事务 1]
A -->|begin| C[分支事务 2]
B -->|before image| D[undo_log]
C -->|before image| D
B -->|commit/rollback| E[RM 资源管理器]
C -->|commit/rollback| E
A --> F[TC 事务协调者]
style A fill:#e76f51
style F fill:#e9c46a
style D fill:#2a9d8fAT 模式 3 个状态:
| 状态 | 含义 | 后续动作 |
|---|
| 待提交 | 一阶段已完成 | 等待二阶段 |
| 已提交 | 二阶段 commit | 删除 undo_log |
| 已回滚 | 二阶段 rollback | 删除 undo_log |
Step 2:定位悬挂
1
2
3
4
5
6
7
8
9
10
| -- 看悬挂事务
SELECT
xid,
branch_id,
log_status,
log_created,
log_modified
FROM undo_log
WHERE log_status = 0
ORDER BY log_created DESC;
|
输出:
1
2
| xid branch_id log_status log_created log_modified
192.168.1.1:8091:123456 1 0 2026-06-09 03:30:00 2026-06-09 03:30:00
|
3 小时前的事务还在"待提交" —— 悬挂!
Step 3:找根因
Seata 悬挂的 4 种情况:
| 情况 | 现象 | 根因 |
|---|
| 分支注册失败 | undo_log 写了,TC 不知道 | RM 端失败重试 |
| TC 长时间不响应 | RM 端超时,事务没结束 | TC 性能问题 |
| 网络分区 | TM 和 TC 失联 | 网络抖动 |
| TM 异常崩溃 | 二阶段没发 | 进程崩溃 |
Step 4:代码定位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 经典 Seata AT 代码
@GlobalTransactional(name = "order-create", rollbackFor = Exception.class)
public Order createOrder(OrderRequest request) {
// 1. 扣库存
storageService.deduct(request.getItems());
// 2. 创建订单
Order order = orderRepository.save(build(request));
// 3. 扣账户
accountService.debit(request.getUserId(), request.getAmount());
return order;
}
|
如果 step 2 失败:
- 库存已扣,订单未创建
- undo_log 写了"扣库存前"的镜像
- 等待二阶段回滚
如果 step 3 失败:
- 库存已扣,订单已创建
- undo_log 写了"扣账户前"的镜像
- 等待二阶段回滚
11.4 根因分析
悬挂的本质:分支事务执行了,但全局协调者(TC)不知道该不该回滚。
11.5 修复 + 改进方案
修复 1:状态补偿(手动)
1
2
3
4
5
6
7
8
9
| -- 找出悬挂事务
SELECT * FROM undo_log
WHERE log_status = 0
AND log_modified < DATE_SUB(NOW(), INTERVAL 10 MINUTE);
-- 手动回滚(按业务判断)
-- 比如:扣库存失败、订单未创建 → 释放库存
UPDATE stock SET quantity = quantity + 1 WHERE product_id = 12345;
DELETE FROM undo_log WHERE branch_id = 67890;
|
修复 2:业务层防悬挂
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // 加本地消息表(最终一致性)
@GlobalTransactional
public Order createOrder(OrderRequest request) {
// 1. 防重(幂等)
String idempotentKey = "order:create:" + request.getOrderId();
if (redisTemplate.hasKey(idempotentKey)) {
return orderRepository.findById(request.getOrderId());
}
redisTemplate.opsForValue().set(idempotentKey, "1", 1, TimeUnit.HOURS);
// 2. 扣库存
storageService.deduct(request.getItems());
// 3. 写本地消息表(异步)
messageService.saveLocal(new OrderMessage(request));
// 4. 创建订单
Order order = orderRepository.save(build(request));
return order;
}
|
修复 3:避免 Seata AT 的限制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| // 用 TCC 替代 AT(业务侵入大,但可控)
@TwoPhaseBusinessAction(name = "deductStock")
public class DeductStockTcc implements TccAction {
@Override
public boolean prepare(BusinessActionContext ctx, Long productId, Integer count) {
// Try:扣库存
return stockRepository.deduct(productId, count) > 0;
}
@Override
public boolean commit(BusinessActionContext ctx) {
// Confirm:确认(Try 成功才走)
return true;
}
@Override
public boolean rollback(BusinessActionContext ctx) {
// Cancel:回滚
return stockRepository.add(ctx.getProductId(), ctx.getCount()) > 0;
}
}
|
防御方案
| 维度 | 方案 |
|---|
| 幂等 | 所有外部调用加 idempotent key |
| 补偿 | 本地消息表 + 定时对账 |
| 监控 | 监控 undo_log 滞留数 |
| 告警 | 5 分钟未结束事务告警 |
| 演练 | 每月一次"分布式事务演练" |
| SLA | 全局事务 95% 在 5 秒内结束 |
🛑 误区警示:能不用分布式事务就别用
99% 的分布式事务场景可以用业务设计绕开:
- 预占库存 + 异步扣减:先扣减本地"冻结库存",再异步通知真正扣减
- 本地消息表:事务和消息都写入本地表,异步发送
- 对账兜底:T+1 对账,保证最终一致
分布式事务 = 复杂 + 性能差 + 难调试,是最后手段。
11.6 实战 Runbook(Seata 事故标准操作步骤)
适用情景:发现订单状态卡住,undo_log 有未完成事务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| # 步骤 1:检查悬挂(30 秒)
mysql -u root -p -e "
SELECT xid, branch_id, log_status, log_created
FROM undo_log
WHERE log_status = 0
AND log_created < DATE_SUB(NOW(), INTERVAL 5 MINUTE);"
# 步骤 2:通知 TC 服务(1 分钟)
# 检查 seata-server 健康
curl http://seata-server:8091/health
# 步骤 3:手动补偿(5-30 分钟)
# 原则:让业务继续运行,手工对账
# - 订单未创建 → 释放库存
# - 账户未扣减 → 提示用户重试
# - 库存未回滚 → 调整库存
# 步骤 4:补单(10 分钟)
# 写脚本批量修复订单状态
|
11.7 备选方案对比
| 方案 | 一致性 | 性能 | 复杂度 | 适用 |
|---|
| Seata AT | 最终 | 中 | 中 | 通用业务 |
| Seata TCC | 强 | 好 | 高 | 金融 |
| Seata Saga | 最终 | 好 | 中 | 长事务 |
| 本地消息表 | 最终 | 好 | 低 | 99% 场景 |
| 消息队列 | 最终 | 好 | 中 | 跨服务 |
| 2PC (XA) | 强 | 差 | 中 | 数据库同构 |
📌 实战经验:某金融从 Seata AT 切到本地消息表
切换原因:Seata AT 模式下 RT 增加 30%,长事务导致 undo_log 暴涨
切换方案:
- 订单创建 + 扣库存拆为本地事务
- 用 RocketMQ 事务消息保证最终一致
- 每日 T+1 对账兜底
切换后收益:
- RT 从 250ms 降到 80ms(提升 3 倍)
- 业务复杂度下降 50%
- 事务悬挂事故 0 起(原本每月 2-3 起)
十二、场景 10:分布式链路追踪定位慢节点
12.1 现象
- 用户反馈:下单慢(15s+)
- 监控:服务 P99 正常,但用户感知慢
- 业务:某条链路涉及 6 个服务,不知道慢在哪
- 日志:每条日志都看,但跨服务串不起来
12.2 应急止血
1
2
3
4
5
6
7
| # 1. 从 SkyWalking UI 找慢 trace
# 服务 → Trace → 排序(耗时)→ 找 P99 异常的
# 2. 临时降级非核心服务
# 关闭推荐 / 营销 / 风控 → 验证主链路
# 3. 切流量到历史稳定版本
|
12.3 排查过程
Step 1:SkyWalking UI 看 trace
1
2
3
4
5
6
7
8
9
10
11
12
| Trace ID: 7a3f.1234567890.01
服务: order-service
入口: /api/order/create
总耗时: 8.42s
调用链:
gateway 80ms
order-service 2.10s
check-stock 45ms
pay-service 5.80s ← 慢!
redis-call 4.20s ← 罪魁祸首
db-update 1.40s
notify 220ms
|
一眼看出:pay-service 的 redis-call 慢(4.2s)。
Step 2:在 ELK 中查这条 trace 的日志
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # 在 Kibana 中搜
traceId: 7a3f.1234567890.01
# 输出:
2026-06-09 14:23:45.123 INFO [http-nio-8080-exec-25] [traceId=7a3f.1234567890.01]
c.e.pay.PayService - enter pay, orderId=10086
2026-06-09 14:23:45.123 INFO [http-nio-8080-exec-25] [traceId=7a3f.1234567890.01]
c.e.pay.PayService - start redis call
2026-06-09 14:23:49.323 WARN [http-nio-8080-exec-25] [traceId=7a3f.1234567890.01]
c.e.pay.PayService - redis call slow, cost=4200ms, key=pay:lock:10086
2026-06-09 14:23:49.323 ERROR [http-nio-8080-exec-25] [traceId=7a3f.1234567890.01]
c.e.pay.PayService - redis call timeout
|
完整还原:redis 调 pay:lock:10086 慢,4.2 秒才返回。
Step 3:找慢调用代码
1
2
3
4
5
6
7
8
9
10
11
| // 看 redis 调用代码
public PayResult pay(String orderId) {
String lockKey = "pay:lock:" + orderId;
// 慢点:这是大 key 吗?
// pay:lock:10086 是 HASH,存了 10 万条记录(用户每支付一次加一条,永不过期)
RLock lock = redissonClient.getLock(lockKey);
lock.lock(5, TimeUnit.SECONDS);
// ... 业务
}
|
12.4 根因分析
慢节点 4 大原因:
| 原因 | 占比 | 修复 |
|---|
| 下游 RT 高 | 40% | 优化下游 / 缓存 / 异步 |
| DB 慢 | 25% | 索引 / SQL 优化 |
| Redis 慢 | 15% | 大 key / 热 key |
| 锁竞争 | 10% | 减小锁粒度 |
| JVM 慢 | 10% | GC / CPU |
12.5 修复 + 改进方案
修复 1:临时方案 - 异步化
1
2
3
4
5
6
7
8
9
10
11
| // 同步改异步
@Async
public CompletableFuture<PayResult> payAsync(String orderId) {
return CompletableFuture.completedFuture(doPay(orderId));
}
// 立即返回,让前端轮询
public Order create(OrderRequest request) {
String taskId = taskService.submit(request);
return Order.pending(taskId);
}
|
修复 2:缓存热点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 用本地缓存 + Redis 二级缓存
public PayResult pay(String orderId) {
String cacheKey = "pay:result:" + orderId;
PayResult cached = caffeineCache.getIfPresent(cacheKey);
if (cached != null) return cached;
cached = redisTemplate.opsForValue().get(cacheKey);
if (cached == null) {
cached = doPay(orderId);
redisTemplate.opsForValue().set(cacheKey, cached, 5, TimeUnit.MINUTES);
}
caffeineCache.put(cacheKey, cached);
return cached;
}
|
修复 3:锁粒度优化
1
2
3
4
5
6
| // 错:用订单 ID 锁(大 key,1 个订单 1 个锁)
RLock lock = redissonClient.getLock("pay:lock:" + orderId);
// 对:用分段锁
int segment = orderId.hashCode() % 16;
RLock lock = redissonClient.getLock("pay:lock:seg:" + segment);
|
链路追踪体系搭建
graph LR
A[TraceId 生成] --> B[MDC 注入]
B --> C[日志关联]
C --> D[ELK 搜索]
D --> E[SkyWalking UI]
E --> F[告警]
style A fill:#e76f51
style E fill:#2a9d8f监控告警
1
2
3
4
5
6
7
8
9
10
11
12
| # SkyWalking → Prometheus → AlertManager
- alert: SlowTrace
expr: histogram_quantile(0.99, http_server_requests_seconds_bucket{uri="/api/order/create"}) > 5
for: 2m
annotations:
summary: "下单接口 P99 > 5s"
- alert: ServiceErrorRate
expr: rate(http_server_requests_seconds_count{status=~"5.."}[5m]) > 0.1
for: 1m
annotations:
summary: "服务 5xx 错误率 > 10%"
|
12.6 实战 Runbook(慢链路定位步骤)
适用情景:用户反馈下单慢,监控 P99 正常。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # 步骤 1:取样慢 trace(30 秒)
# SkyWalking UI → Trace → 按耗时倒序 → 找 P99 > 5s 的链路
# 步骤 2:找到慢节点(1 分钟)
# 看火焰图:哪一段占比最大
# 例如:pay-service.redis-call 占 50% → 锁定 Redis
# 步骤 3:看对应日志(2 分钟)
# ELK 搜 traceId → 看完整日志链
# 重点:慢在哪一行代码、什么 key、什么参数
# 步骤 4:临时方案(5 分钟)
# - 缓存预热
# - 异步化
# - 限流降级
# 步骤 5:永久方案(后续)
# - 拆分大 key
# - 优化 SQL
# - 引入本地缓存
|
12.7 备选方案对比
| 方案 | 部署 | 学习成本 | 性能损耗 | 适用 |
|---|
| SkyWalking | 国产/开源 | 中 | < 3% | 国内首选 |
| Jaeger | CNCF/开源 | 低 | < 5% | 云原生 |
| Zipkin | Twitter/开源 | 低 | < 5% | Spring Cloud 集成 |
| Tempo + Grafana | Grafana 系 | 中 | < 3% | 已有 Grafana |
| Pinpoint | 韩国/开源 | 高 | 5-10% | 韩国电商常用 |
| CAT | 美团/开源 | 中 | < 5% | 美团技术栈 |
📌 实战经验:SkyWalking 调优数据
默认配置下,单 Agent 内存占用 200MB + 5% 性能损耗
调优后:
- 采样率从 100% 改为 10%(错误链路 100%)
- 慢查询阈值设为 500ms
- 链路缓冲 50MB → 200MB
调优后效果:
- 内存占用:200MB → 350MB
- 性能损耗:5% → 1%
- 存储:每月 50GB → 12GB(采样后)
十三、改进方案:5 层防御体系
13.1 5 层防御模型
graph TD
L1[第 1 层: 代码防御
Code Review + 静态分析] --> L2[第 2 层: 测试防御
单元测试 + 压测 + Chaos]
L2 --> L3[第 3 层: 监控防御
Metrics + Logging + Tracing]
L3 --> L4[第 4 层: 应急防御
Runbook + 值班 + 演练]
L4 --> L5[第 5 层: 复盘防御
Postmortem + 改进项跟进]
style L1 fill:#2a9d8f
style L2 fill:#2a9d8f
style L3 fill:#e9c46a
style L4 fill:#e76f51
style L5 fill:#e76f5113.2 第 1 层:代码防御
| 维度 | 工具 / 措施 |
|---|
| 代码 Review | 强制 PR + 2 人 + Lint 规则 |
| 静态分析 | SonarQube + SpotBugs + Checkstyle |
| 依赖检查 | OWASP Dependency-Check |
| 代码规范 | 阿里 Java 手册 + Google Style |
| Git Hook | pre-commit 跑测试 + 格式检查 |
13.3 第 2 层:测试防御
| 维度 | 工具 / 措施 |
|---|
| 单元测试 | JUnit 5 + Mockito + 覆盖率 > 80% |
| 集成测试 | Testcontainers(真实 DB/Redis/MQ) |
| 压测 | JMeter / Gatling / wrk |
| 混沌工程 | ChaosBlade / Chaos Monkey |
| 故障演练 | 每月一次"红蓝对抗" |
13.4 第 3 层:监控防御(三大支柱)
graph LR
M[Metrics
Prometheus] --> G[Grafana
大盘]
L[Logging
ELK] --> K[Kibana
搜索]
T[Tracing
SkyWalking] --> S[SkyWalking UI
调用链]
style M fill:#2a9d8f
style L fill:#e9c46a
style T fill:#e76f51Metrics(指标):
| 必埋指标 | 阈值 |
|---|
| CPU / MEM / DISK / NET | > 80% 告警 |
| QPS / RT / 错误率 | P99 > 1s |
| GC 频率 / STW | Full GC > 1/min |
| 线程数 / BLOCKED | > 1000 |
| DB 连接池 / 慢 SQL | > 80% / > 1s |
Logging(日志):
| 必含字段 | 必埋日志 |
|---|
| traceId / userId / uri | 入口 + 出口 |
| request / response | 外部调用 |
| exception stack | 错误 |
| 慢调用 (> 1s) | 性能 |
Tracing(追踪):
| 必埋 | 工具 |
|---|
| HTTP 调用 | OpenTelemetry |
| DB 调用 | JDBC 拦截器 |
| Redis 调用 | Lettuce/Jedis 拦截器 |
| MQ 调用 | Kafka Client 拦截器 |
| 内部调用 | Spring AOP |
13.5 第 4 层:应急防御
Runbook(操作手册)—— 每个服务必须有:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # OrderService 应急 Runbook
## P0:服务不可用
### 1. 摘流量
kubectl scale deployment order-service --replicas=0
### 2. 切历史版本
kubectl rollout undo deployment order-service
### 3. 联系值班
@oncall
## P1:响应慢
### 1. 看监控
Grafana → OrderService → P99 Latency
### 2. 看 GC
jstat -gcutil <pid> 1s
### 3. 看慢 SQL
MySQL → slow_log → ORDER BY start_time DESC
|
值班制度:
- 7×24 主备值班
- 告警 < 5 分钟响应
- 工单系统 + 飞书 / 钉钉
13.6 第 5 层:复盘防御
Postmortem(事故复盘)模板:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| # 事故复盘:[标题]
## 基本信息
- 时间:2026-06-09 03:47
- 影响:订单服务不可用 23 分钟
- 损失:47 万元
## 时间线
- 03:47 告警触发
- 03:50 应急响应启动
- 03:55 流量切走
- 04:10 定位根因
- 04:20 修复上线
- 04:30 恢复
## 根因
[技术原因 + 业务原因]
## 改进项
- [ ] 短期(1 周):加监控 + 限流
- [ ] 中期(1 月):重构 + 压测
- [ ] 长期(1 季):架构升级
## 教训
[可推广的经验]
|
复盘原则:
- 对事不对人:不追究个人责任
- 24 小时内:出复盘报告
- 改进项跟进:必须录入 Jira/禅道
- 每月 review:未关闭项要升级
13.6 5 层防御的 3 个真实落地案例
案例 1:某电商从 P0 月均 5 起降到月均 0.5 起
| 阶段 | 措施 | 效果 |
|---|
| 第 1 个月 | 完善 Metrics + Logging + Tracing 三大支柱 | 事故定位时间 30 分钟 → 5 分钟 |
| 第 2 个月 | 全员 Runbook 培训 + 每月故障演练 | 应急响应 15 分钟 → 3 分钟 |
| 第 3 个月 | 代码 Review 强制 + SonarQube 卡点 | 引入 bug 数 -60% |
| 第 6 个月 | 混沌工程 ChaosBlade 接入 | 主动发现问题 -80% |
P0 事故次数:5 → 2 → 1 → 0.5
案例 2:某金融核心系统 7 层防御升级
- 代码层:SonarQube 卡点 + 强制单测覆盖率 > 80%
- 测试层:Testcontainers + Pact 契约测试
- 监控层:Prometheus + SkyWalking + ELK 三件套
- 告警层:AlertManager + 钉钉 + 电话多通道
- 应急层:Runbook + 7×24 值班 + 一键降级开关
- 复盘层:Postmortem 模板 + 改进项工单
- 文化层:月度故障演练 + 红蓝对抗
案例 3:某 SaaS 平台事故成本对比
| 维度 | 防御体系前 | 防御体系后 |
|---|
| P0 事故 | 8 次/月 | 1 次/月 |
| 平均 MTTR | 47 分钟 | 8 分钟 |
| 月损失 | 120 万元 | 15 万元 |
| 客户投诉 | 80+/月 | 5-/月 |
| 工程师加班 | 频繁 | 偶尔 |
📌 实践:5 层防御的 ROI 拐点
- 第 1 层(代码) 投入产出比最高(1 倍投入,10 倍回报)
- 第 3 层(监控) 必备(1 倍投入,5 倍回报)
- 第 4 层(应急) 必须(1 倍投入,3 倍回报)
- 第 2 层(测试) 长期投资(1 倍投入,2 倍回报)
- 第 5 层(复盘) 隐性收益(难量化但价值最大)
建议:从代码 + 监控开始,逐步推进。
13.7 第 1 层:代码防御深度展开
为什么代码层是性价比最高的一层?
| 问题 | 在代码层 | 在生产层 | 倍数 |
|---|
| 发现 bug 成本 | 1 元 | 100 元 | 100 倍 |
| 修复时间 | 1 小时 | 1 天 | 24 倍 |
| 业务影响 | 0 用户 | 100 万用户 | ∞ |
代码防御的 7 大实操:
- 强制 Code Review:所有 PR 必须 2 人 Review(不包括自己)
- SonarQube 卡点:覆盖率 < 80% 不允许合并
- Lombok 谨慎使用:生成的代码 Review 看不到
- 静态分析工具:
- SpotBugs:发现 NPE、资源泄漏、并发问题
- Checkstyle:阿里 Java 手册规则
- PMD:代码重复、复杂度过高
- 依赖扫描:
mvn dependency-check:check 检查漏洞 - Git Hook:pre-commit 跑 Lint + 单元测试
- AI 辅助:用 Claude Code / Copilot 做 PR 评审
13.8 第 3 层:监控防御深度展开
监控的 3 个等级:
| 等级 | 含义 | 例子 |
|---|
| L1 - 业务监控 | 业务结果 | 订单数、GMV、注册数 |
| L2 - 应用监控 | 中间状态 | QPS、RT、错误率、并发数 |
| L3 - 资源监控 | 物理状态 | CPU、内存、磁盘、网络 |
必埋的 7 大黄金指标:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # 1. 业务黄金信号
business.order.count: rate > 100/s
business.order.amount: rate > 10000元/s
# 2. 接口信号
http_server_requests_seconds{quantile="0.99"}: P99 < 1s
http_server_requests_seconds_count{status=~"5.."}: 5xx < 0.1%
# 3. JVM 信号
jvm_memory_old_gen_used_bytes / jvm_memory_old_gen_max_bytes: < 80%
jvm_gc_pause_seconds{quantile="0.99"}: < 500ms
jvm_threads_states{state="BLOCKED"}: < 100
# 4. 资源信号
node_cpu_utilization: < 80%
node_memory_utilization: < 80%
node_disk_utilization: < 80%
|
13.9 第 4 层:应急防御深度展开
Runbook 必须包含的 10 个要素:
- 服务基本信息(端口、依赖、负责人)
- P0 / P1 / P2 应急步骤
- 降级开关(Nacos 配置开关名)
- 摘流量命令(K8s / Nginx)
- 回滚命令(版本号 + 步骤)
- 联系人员(主备 + 上下游负责人)
- 常见问题 FAQ(从 Postmortem 沉淀)
- 依赖文档(DB / Redis / MQ 地址)
- 监控大盘(Grafana Dashboard 链接)
- 变更记录(最近 5 次发布 + 变更点)
值班制度的 3 个关键指标:
| 指标 | 目标 | 测量方法 |
|---|
| MTTA(Mean Time To Acknowledge) | < 5 分钟 | 告警到值班响应时间 |
| MTTR(Mean Time To Recover) | < 30 分钟 | 告警到服务恢复 |
| MTBF(Mean Time Between Failures) | > 1 周 | 两次 P0 事故间隔 |
📌 实践:值班 KPI 设计
优秀值班:
- 告警响应时间 < 5 分钟
- 一次解决率 > 80%
- 复盘改进项 100% 跟进
末位值班:
- MTTA > 15 分钟
- 二次升级 > 50%
- 复盘改进项未跟进
13.10 第 5 层:复盘防御深度展开
Postmortem 模板的 8 个必备部分:
- 事故基本信息:时间、影响范围、损失估算
- 时间线:精确到分钟(含告警、响应、定位、修复、恢复)
- 根因分析:5-Why 直到业务原因
- 影响范围:受影响用户数、订单数、金额
- 应急处理:实际做了哪些动作
- 改进项:短期/中期/长期 + 负责人 + 完成时间
- 经验教训:可推广到其他团队
- 预防措施:如何避免再次发生
复盘会议的 4 个铁律:
- 准时开始:超过 5 分钟就延后
- 提前发资料:会前 24 小时发
- 不超过 1 小时:超时下次继续
- 输出明确:改进项必须有 owner
十四、总结 + Checklist + FAQ
14.1 10 大场景速查表
| # | 场景 | 一句话定位 | 关键工具 |
|---|
| 1 | CPU 100% | 抓 CPU 线程 → 看栈 | jstack + async-profiler |
| 2 | 内存 OOM | 抓 dump → MAT 分析 | jmap + MAT |
| 3 | 线程死锁 | jstack 自动检测 | jstack -b |
| 4 | FullGC | jstat 看频率 → 看 log | jstat -gcutil |
| 5 | 慢 SQL | trace → EXPLAIN | Arthas trace + MySQL slow log |
| 6 | 接口雪崩 | Sentinel 控制台 | Sentinel + Resilience4j |
| 7 | Redis 大 key | –bigkeys → 拆分 | redis-cli + 拆分 |
| 8 | MQ 积压 | consumer-groups | Kafka Tools + 异步化 |
| 9 | 事务悬挂 | undo_log 检查 | Seata + 幂等 |
| 10 | 链路追踪 | SkyWalking Trace | SkyWalking + ELK |
14.2 应急 5 步速记(USEDG)
1
2
3
4
5
| U - Understand 看监控 1 分钟
S - Stop 摘流量 5 分钟
E - Explore 查根因 15 分钟
D - Diagnose 写代码 30 分钟
G - Guard 写预案 后续
|
14.3 必装工具清单
1
2
3
4
5
6
| # JDK 自带:jps, jstack, jmap, jstat, jcmd, jinfo
# 阿里 Arthas:arthas-boot.jar
# 异步分析:async-profiler
# 堆分析:Eclipse MAT
# 数据库:mycli, pt-query-digest
# 通用:htop, iotop, nethogs, strace, lsof
|
14.4 FAQ
Q1:CPU 100% 但 jstack 显示大部分线程是 WAITING?
A:WAITING 不消耗 CPU。用 top -Hp 找真正忙的线程,jstack 找 nid=0x<hex> 对应线程。
Q2:内存 OOM 但 jmap 抓的 dump 很小?
A:可能是直接内存(DirectBuffer) OOM。dump 抓的是堆,直接内存不在堆里。
- 解决:用
jcmd <pid> VM.native_memory summary 看 - Netty 用
-XX:MaxDirectMemorySize=512m 限制
Q3:FullGC 频繁但 dump 里没大对象?
A:是分配速率问题,不是内存泄漏。
- 用
jstat -gc <pid> 1s 看每秒分配量 - 业务在循环内 new 大对象(XML 解析、JSON 序列化)
Q4:Arthas attach 不上?
A:检查 3 件事:
- 进程是否运行(
jps) - 端口冲突(
lsof -i:3658) - jdk 版本(Arthas 3.6+ 需要 JDK 8+)
Q5:分布式事务怎么选?
A:99% 用最终一致性(本地消息表 + 对账),只有金融核心用 TCC 或 Seata AT。
Q6:线上能直接改代码吗?
A:不能直接改源码。Arthas 可以:
ognl 改运行时值(开关位、限流阈值)jad + mc + redefine 热更新(谨慎,5% 失败率)
Q7:怎么知道"事故已经恢复了"?
A:3 个信号同时满足:
- 监控 P99 回到基线
- 业务人工验证 OK
- 错误率 < 0.1% 持续 10 分钟
Q8:值班该看哪些?
A:Grafana 大盘 + 核心 5 指标:
1
2
3
4
5
| 1. 业务黄金指标(QPS / 错误率 / P99)
2. JVM 指标(GC / 内存 / 线程)
3. 资源指标(CPU / 内存 / 磁盘 / 网络)
4. 依赖指标(DB / Redis / MQ)
5. 告警事件(实时滚动)
|
14.5 系列预告
这是 Java Web 微服务系列 的第 9 篇。后续计划:
- Spring Cloud Alibaba 实战:Nacos + Sentinel + Seata 三件套
- 可观测性体系:Metrics + Logging + Tracing 完整搭建
- K8s 深度实践:从 Pod 到 Operator
- 多活架构:单元化、流量调度、灰度发布
- 性能优化专题:JVM 调优 + 线程池 + 连接池
十五、推荐阅读 + 参考文章
官方文档:
经典书籍:
- 《深入理解 Java 虚拟机》(周志明)—— JVM 圣经
- 《Java 性能权威指南》(Scott Oaks)—— 性能调优必读
- 《SRE:Google 运维解密》(Beyer 等)—— SRE 思想源头
- 《数据密集型应用系统设计》(Martin Kleppmann)—— 分布式系统
- 《Effective Java》(Joshua Bloch)—— Java 编码最佳实践
技术博客:
开源项目:
参考文章
💡 学习路径建议
- 入门:本文 + Arthas 官方文档,2 周能上手
- 进阶:JVM 调优 + SkyWalking 源码,1 个月精通
- 实战:每月做一次"故障演练",把方法论用熟
- 深潜:读 Arthas 源码(建议从
core/src/main/java/arthas/ 入口),理解 Java Attach API
理论 + 实践 + 演练,缺一不可。线上排查不是"看几篇文章就会的",必须真刀真枪干过几次。