在高并发系统中,限流(Rate Limiting)是保护下游服务不被突发流量打挂的核心手段。限流算法家族里,最常见的 4 个成员是:固定窗口计数器、滑动窗口计数器、漏桶算法、令牌桶算法。它们各有取舍,分别适用于不同的业务场景。这篇文章会带你用 4 张原理图 + 代码实现 + 选型建议,把这 4 个算法彻底讲透。
为什么学限流? 限流是后端面试几乎必考的题目(无论是社招还是校招),因为它同时考察你算法理解、并发编程、系统设计三大能力。更重要的是,主流的微服务网关(Spring Cloud Gateway / Sentinel / Kong / Envoy)底层都跑着这些算法。
一、为什么需要限流?
在动手学算法之前,先搞清楚"限流到底在防什么":
| 风险 | 说明 |
|---|
| 雪崩 | 一个慢下游拖垮整个调用链 |
| 资源耗尽 | 数据库连接池/线程池被打满 |
| 恶意流量 | 爬虫/羊毛党/CC 攻击 |
| 突发流量 | 秒杀、热点事件、明星离婚导致 10x 流量尖刺 |
限流的目标是:在系统容量范围内接待尽可能多的"好"请求,把"坏"请求挡在外面。
二、固定窗口计数器(Fixed Window Counter)
2.1 算法原理
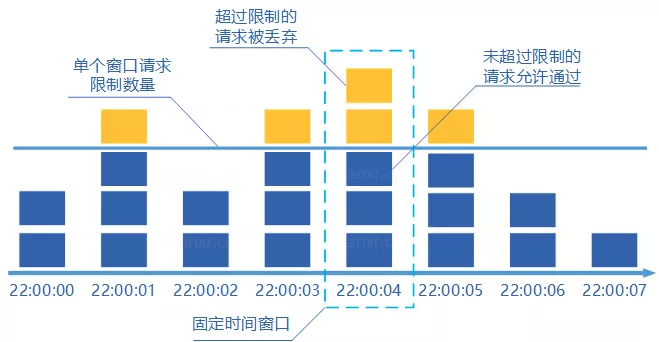
图源说明:上图来自原 限流/算法.md 文档,展示了固定窗口计数器把时间轴切成等长窗口(图中每个矩形就是一个窗口),每个窗口内独立计数的结构。
核心思想:
- 将时间划分为多个等长的窗口(例如 1 秒一个窗口)
- 在每个窗口内每来一个请求就将计数器加一
- 如果计数器超过了限制数量,则本窗口内所有的请求都被丢弃
- 当时间到达下一个窗口时,计数器重置
2.2 致命缺陷:边界双倍突发
固定窗口是最简单的算法,但有一个著名的"边界问题"——它可能让通过请求量允许为限制的两倍。
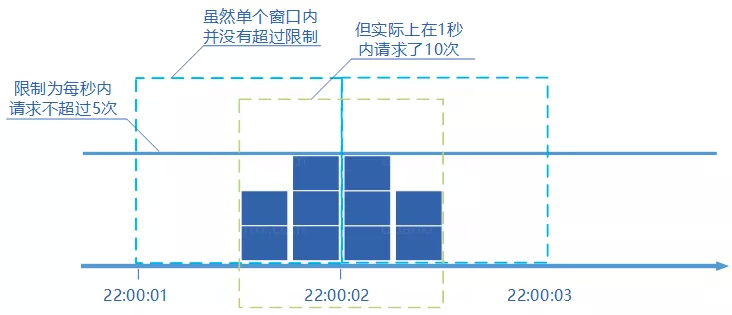
图源说明:上图演示了"边界双倍突发"问题。
例子:限制 1 秒内最多通过 5 个请求。
- 第 1 个窗口的最后半秒:通过了 5 个请求
- 第 2 个窗口的前半秒:又通过了 5 个请求
看起来是在 1 秒内通过了 10 个请求——两倍于限制!系统在临界点承受了远超设计容量的压力。
2.3 代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import time
class FixedWindowRateLimiter:
"""固定窗口计数器:实现最简单,但有边界双倍突发的风险"""
def __init__(self, limit: int, window_seconds: int):
self.limit = limit
self.window = window_seconds
self.count = 0
self.window_start = int(time.time())
def allow(self) -> bool:
now = int(time.time())
if now - self.window_start >= self.window:
# 进入新窗口
self.window_start = now
self.count = 0
if self.count < self.limit:
self.count += 1
return True
return False
|
2.4 优缺点
| 优点 | 缺点 |
|---|
| 实现最简单(一个计数器 + 一个时间戳) | 边界双倍突发问题 |
| 内存占用最小 | 窗口切换时可能"突然丢一半请求" |
| 单机/分布式都好实现 | 不适合"严格平滑限流"的场景 |
三、滑动窗口计数器(Sliding Window Counter)
3.1 算法原理
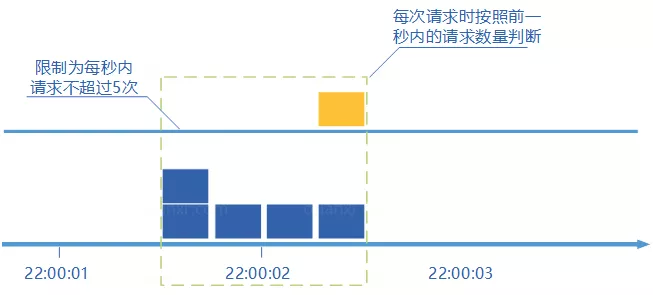
图源说明:上图展示了滑动窗口计数器把每个窗口再细分成多个小时间区间,并按时间"滑动"的机制。
核心思想:
- 将时间划分为多个小时间区间(如 1 秒的窗口再分成 10 个 100ms 的子区间)
- 在每个子区间内每来一个请求就将该子区间的计数器加一
- 维持一个时间窗口,占据多个子区间
- 每经过一个子区间的时间,则抛弃最老的一个子区间,并纳入最新的一个子区间
- 如果当前窗口内所有子区间的请求计数总和超过了限制数量,则本窗口内所有的请求都被丢弃
3.2 为什么解决了边界问题?
滑动窗口通过"细分 + 滑动"避免了固定窗口的双倍突发——窗口的边界是连续滑动的,不会突然从一个干净状态跳到满载状态。
3.3 精度与空间的权衡
| 子区间数量 | 精度 | 内存占用(每个用户) |
|---|
| 1(=固定窗口) | 最粗 | O(1) |
| 10 | 中 | O(10) |
| 60 | 细 | O(60) |
| 1000 | 很高 | O(1000) |
子区间越多,限流越精准,但每个用户/接口的内存占用越大。Cloudflare 公开的方案里就用 60 个子区间的滑动窗口。
3.4 代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import time
from collections import deque
class SlidingWindowRateLimiter:
"""滑动窗口计数器:精度高,能避免固定窗口的边界双倍突发"""
def __init__(self, limit: int, window_seconds: int):
self.limit = limit
self.window = window_seconds
# 存 (时间戳, ),每次清理掉超过 window 的旧时间戳
self.timestamps: deque[float] = deque()
def allow(self) -> bool:
now = time.time()
# 弹出过期的时间戳
while self.timestamps and self.timestamps[0] <= now - self.window:
self.timestamps.popleft()
if len(self.timestamps) < self.limit:
self.timestamps.append(now)
return True
return False
|
3.5 优缺点
| 优点 | 缺点 |
|---|
| 解决了固定窗口的边界问题 | 内存占用更大 |
| 精度可调 | 实现稍复杂 |
| 适合 API 限流、爬虫限频 | 单机原子性需要锁/原子操作 |
四、漏桶算法(Leaky Bucket)
4.1 算法原理
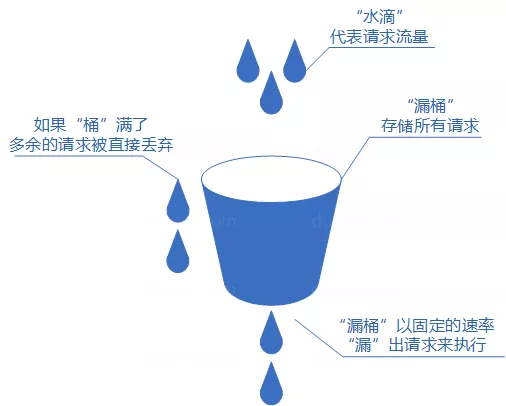
图源说明:上图展示了漏桶算法把请求视作"水滴"放入"漏桶",再以固定速率向外"漏"出请求的机制。
核心思想:
- 将每个请求视作"水滴"放入"漏桶"进行存储
- “漏桶"以固定速率向外"漏"出请求来执行
- 如果"漏桶"空了则停止"漏水”
- 如果"漏桶"满了则多余的"水滴"会被直接丢弃
4.2 核心特性:强制平滑输出
漏桶最大的特点是输出速率恒定——无论进来的流量多不均匀,出去的速率永远是 leak_rate。这非常适合"下游服务处理能力固定“的场景(如调用银行接口、调用第三方 API)。
4.3 缺陷:无法应对突发
漏桶的缺陷也很明显——当短时间内有大量的突发请求时,即便此时服务器没有任何负载,每个请求也都得在队列中等待一段时间才能被响应。换句话说:它把"突发"给"抹平"了。
4.4 代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import time
from collections import deque
class LeakyBucketRateLimiter:
"""漏桶算法:强制平滑输出,适合下游处理能力固定的场景"""
def __init__(self, capacity: int, leak_rate_per_sec: float):
"""
:param capacity: 桶容量
:param leak_rate_per_sec: 每秒漏出的水滴数
"""
self.capacity = capacity
self.leak_rate = leak_rate_per_sec
self.queue: deque[float] = deque()
self.last_leak_time = time.time()
def _leak(self):
"""把超过当前时间该漏出的水滴都漏掉"""
now = time.time()
elapsed = now - self.last_leak_time
leaked = int(elapsed * self.leak_rate)
if leaked > 0:
for _ in range(min(leaked, len(self.queue))):
self.queue.popleft()
self.last_leak_time = now
def allow(self) -> bool:
self._leak()
if len(self.queue) < self.capacity:
self.queue.append(time.time())
return True
return False
|
4.5 优缺点
| 优点 | 缺点 |
|---|
| 输出绝对平滑,保护下游 | 抹掉突发——空闲时也无法利用富余容量 |
| 队列机制天然支持"等待"语义 | 需要额外的队列/定时器 |
| 实现直观 | 延迟 = 队列长度 / 漏出速率 |
五、令牌桶算法(Token Bucket)
5.1 算法原理
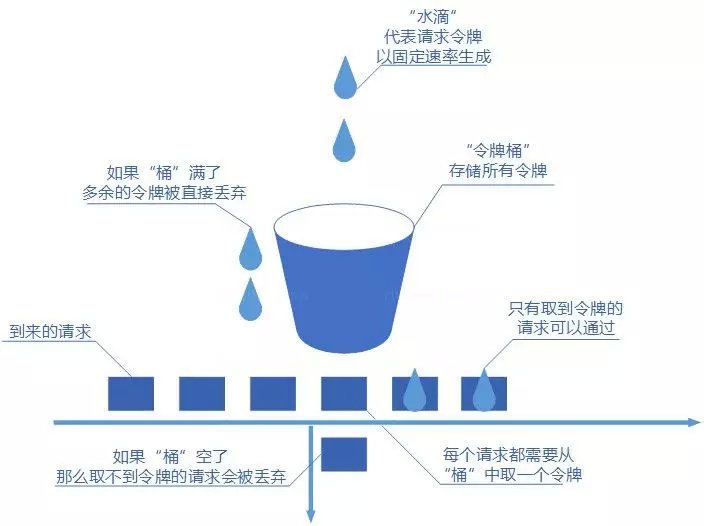
图源说明:上图展示了令牌桶算法以固定速率生成令牌、请求来临时取令牌的工作机制。
核心思想:
- 令牌以固定速率生成
- 生成的令牌放入令牌桶中存放,如果令牌桶满了则多余的令牌会直接丢弃
- 当请求到达时,会尝试从令牌桶中取令牌
- 取到了令牌的请求可以执行
- 如果桶空了,那么尝试取令牌的请求会被直接丢弃
5.2 为什么是"工业界默认”?
令牌桶既能够将所有的请求平均分布到时间区间内,又能接受服务器能够承受范围内的突发请求——这两点恰好是漏桶和固定窗口都做不到的:
- 平均限流:长期平均速率 = 令牌生成速率
- 允许突发:桶里积攒的令牌可以一次性被突发请求用完
- 平滑降级:桶空了就拒绝,不会让下游被打挂
因此 Guava RateLimiter、Nginx limit_req、AWS API Gateway、Spring Cloud Gateway 等都默认使用令牌桶或它的变体。
5.3 代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import time
import threading
class TokenBucketRateLimiter:
"""令牌桶算法:兼顾平滑限流 + 允许突发,是工业界最常用的限流算法"""
def __init__(self, capacity: int, refill_rate_per_sec: float):
"""
:param capacity: 桶容量(即最大突发量)
:param refill_rate_per_sec: 每秒生成的令牌数(平均限流速率)
"""
self.capacity = capacity
self.refill_rate = refill_rate_per_sec
self.tokens = float(capacity) # 初始满桶
self.last_refill_time = time.time()
self._lock = threading.Lock()
def allow(self, cost: float = 1.0) -> bool:
with self._lock:
now = time.time()
# 补充令牌:自上次以来应该生成的令牌数
elapsed = now - self.last_refill_time
self.tokens = min(self.capacity, self.tokens + elapsed * self.refill_rate)
self.last_refill_time = now
# 取令牌
if self.tokens >= cost:
self.tokens -= cost
return True
return False
|
5.4 优缺点
| 优点 | 缺点 |
|---|
| 兼顾平均限流 + 突发 | 实现比固定/滑动窗口复杂 |
| 工业界事实标准 | 桶容量需要根据业务调优 |
| Guava / Nginx / Sentinel 都内置 | 分布式实现需要原子操作(Redis + Lua) |
六、四大算法对比
| 维度 | 固定窗口 | 滑动窗口 | 漏桶 | 令牌桶 |
|---|
| 时间复杂度 | O(1) | O(N) | O(1) | O(1) |
| 空间复杂度 | O(1) | O(N) | O(队列长) | O(1) |
| 实现难度 | ★ | ★★ | ★★★ | ★★★ |
| 平滑输出 | ✗ | ✗ | ✓ 绝对平滑 | △ 平均平滑、允许突发 |
| 允许突发 | △ 边界双倍 | △ | ✗ 抹平突发 | ✓ 可控突发 |
| 边界问题 | ✗ 有 | ✓ 无 | ✓ 无 | ✓ 无 |
| 典型应用 | 简单统计 | Cloudflare | 消息队列 / 网络整形 | API 网关 / Nginx |
七、核心要点与常见坑
7.1 核心 N 点
- 固定窗口有"边界双倍突发"问题——限制 1 秒 5 个,可能 1 秒放 10 个
- 滑动窗口把窗口细分并滑动,是固定窗口的精准化升级,但内存占用和精度成正比
- 漏桶强制平滑输出,抹掉突发——空闲时也无法"加速消化"
- 令牌桶兼顾平均限流 + 可控突发,是工业界事实标准——Guava/Nginx/Sentinel 都用它
- 限流本质是保护下游——算法选型要回答"下游怕什么":怕突发 → 漏桶;怕长期过载 → 令牌桶
- 分布式限流需要共享计数器(Redis + Lua 脚本 / Redis Cell 模块),单机限流直接用进程内限流器即可
7.2 常见 M 个坑
- 混淆"算法粒度"和"限流维度"——限流可以按 IP / User ID / 接口 / 租户,算法本身和粒度无关
- 桶容量设得太大——突发可能把下游打挂
- 桶容量设得太小——失去了"应对正常抖动"的能力
- 漏桶的"等待"语义被忽略——某些业务根本不能等,直接拒绝更友好
- 限流后没有兜底——被拒绝的请求要返回友好的错误(429 + Retry-After)
- 单机限流当成分布式限流用——多机部署时总速率会变成"单机限制 × 机器数"
- 限流开关没接入监控——出问题时根本不知道是谁在打
八、工业级实践
8.1 Guava RateLimiter(单机令牌桶)
1
2
3
4
5
6
7
8
9
10
| // 创建一个每秒生成 5 个令牌的限流器(即平均 200ms 一个)
RateLimiter limiter = RateLimiter.create(5.0);
if (limiter.tryAcquire()) {
// 拿到令牌,处理请求
handleRequest();
} else {
// 没拿到令牌,直接拒绝
return Response.status(429).build();
}
|
8.2 Nginx limit_req(基于令牌桶)
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 定义一个名为 my_limit 的限流区:
# 10m 共享内存大小
# rate=10r/s 平均 10 个请求/秒
# burst=20 桶容量 20(允许最大 20 个突发)
# nodelay 突发请求不延迟直接处理
limit_req_zone $binary_remote_addr zone=my_limit:10m rate=10r/s;
server {
location /api/ {
limit_req zone=my_limit burst=20 nodelay;
proxy_pass http://backend;
}
}
|
8.3 Redis + Lua 分布式令牌桶
单机的 RateLimiter 只对单进程有效,分布式场景需要共享计数器。常见做法是 Redis + Lua 脚本保证原子性:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| -- KEYS[1]: 令牌桶的 key
-- ARGV[1]: 桶容量
-- ARGV[2]: 填充速率(每秒)
-- ARGV[3]: 当前时间戳(秒)
-- ARGV[4]: 请求消耗的令牌数
local capacity = tonumber(ARGV[1])
local rate = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
local cost = tonumber(ARGV[4])
local data = redis.call('HMGET', KEYS[1], 'tokens', 'last_refill')
local tokens = tonumber(data[1]) or capacity
local last_refill = tonumber(data[2]) or now
-- 补充令牌
local elapsed = math.max(0, now - last_refill)
tokens = math.min(capacity, tokens + elapsed * rate)
if tokens >= cost then
tokens = tokens - cost
redis.call('HMSET', KEYS[1], 'tokens', tokens, 'last_refill', now)
redis.call('EXPIRE', KEYS[1], 60) -- 60 秒没访问就清掉
return 1
else
redis.call('HMSET', KEYS[1], 'tokens', tokens, 'last_refill', now)
return 0
end
|
8.4 选型速查
| 场景 | 推荐算法 | 理由 |
|---|
| 简单统计、QPS 监控 | 固定窗口 | 最简单 |
| API 限流、爬虫限频 | 滑动窗口 | 精度高,无边界问题 |
| 调用第三方固定速率 API | 漏桶 | 强制平滑,保护合作方 |
| API 网关、Nginx、Sentinel | 令牌桶 | 兼顾平均 + 突发,工业标准 |
| 秒杀抢购 | 令牌桶 + 排队 | 削峰填谷 |
| 分布式系统 | 令牌桶 + Redis/Lua | 多机共享状态 |
参考资料
