Java Web 微服务系列 · 第 9 篇 · Seata 分布式事务 阅读时长:约 50 分钟 本文写于 2026 年 6 月 配套版本:Seata 1.8+ / Spring Cloud Alibaba 2022.0.0.0 / Spring Boot 3.x / Nacos 2.3.x / MySQL 8 前置阅读:《数据库演化:MySQL → PostgreSQL → 分布式,从单机到 NewSQL 的全链路实战》(系列第 8 篇)
引子:凌晨 3 点被叫醒的那通电话
2018 年 4 月某个凌晨 3 点,我被一阵急促的电话铃声吵醒。电话那头是刚入职的运维小哥,声音发颤:"哥,订单系统出问题了,DB 主从数据对不上,DBA 在抓狂!"
我一边穿衣服一边远程连上去,看到的景象触目惊心:
- 订单库
t_order表有 387 条订单状态是「已支付」,但账户库t_account表对应的 87 条账户余额没扣 - 库存库
t_stock表对应的 120 条商品库存没扣 - 三个库的事务在「订单创建」成功之后分别 commit 到了不同的时间点,但应用层认为这三个 commit 都成功了——因为代码里写的是
try { orderService.create(); } catch ...,订单服务自己用@Transactional提交,库存和账户是 Feign 远程调用,调用方根本管不到对方的事务 - 用户看到的结果是:钱付了,订单显示了,但商家没收到发货通知,库存没扣,超卖
事后排查,这是一段典型的"分布式事务失效“代码——三个独立的本地事务,靠应用层的 try-catch 串起来,任何一个中间环节失败,前面的 commit 都没法回滚。
我开复盘会时说过一句后来被团队当成内部黑话的话:”不是 Seata 不行,是我们在用裸奔的微服务"。
从那以后,我们走上了"分布式事务治理“这条路:
- 第一步:把三个服务的事务统一交给 Seata 协调(AT 模式,业务零侵入)
- 第二步:账务类高一致性场景切到 TCC 模式(Try-Confirm-Cancel 三阶段)
- 第三步:跨域、长周期业务接入 SAGA 模式(补偿子事务)
- 第四步:财务对账等强一致场景保留 XA 模式(DB 原生两阶段)
- 第五步:根据业务场景做模式选型 + 性能压测 + 灾备演练
到 2025 年回头看,分布式事务是 Java 微服务架构的"主血管”——没有它,上层的弹性扩容、服务治理、流量调度全是空中楼阁。一个不严谨的事务治理方案,再好的服务注册、配置中心、网关也救不了你。
本文要回答四个问题:
- Seata 的核心架构是怎么样的?(TC / TM / RM 怎么协作,全局事务生命周期,undo_log 机制,Server 高可用)
- 为什么用 Seata?(单体事务为什么不够用,跟其他方案对比,核心优势是什么)
- 怎么用 Seata?(Server 部署,Client 接入,AT 模式完整 demo,关键配置,实战踩坑)
- 四种模式的应用场景?(AT / TCC / SAGA / XA 各自的适用场景 + 选型决策树 + 实测性能对比)
文章比较长(约 10000 字),建议先看大纲按需跳读,但模式选型决策树那一节建议完整读——选错模式的代价是几个月后才发现的"为什么数据偶尔对不上账"。
本文适合谁:
- 正在做微服务架构选型的架构师——理解 Seata 4 种模式的适用边界
- 负责电商 / 金融 / 跨境业务的后端开发——能照搬 AT / TCC 模式的完整 demo
- 排查过"数据不一致"问题的SRE / DBA——从架构层理解为什么会出问题
- 准备系统架构师 / 软考架构考试的考生——分布式事务是高频考点
本文不适合谁:
- 已经在用 Seata 且生产稳定的团队——内容偏入门,建议直接看 4.5 选型决策树 + 4.6 混合模式
- 业务量很小的单体应用——本地事务完全够用,引入 Seata 反而过度设计
- 强依赖 Oracle RAC 或 DB 原生 XA 集群的传统金融——直接用 DB 的 XA 事务更省事
读完这篇你应该能回答:Seata 是什么、为什么需要它、怎么落地、4 种模式怎么选。如果某个点讲得不够清楚或者想深入某个模式,评论区留言,我会在系列第 12 篇「Seata 实战踩坑全记录」里挑高频问题做专题。
一、核心架构
很多介绍 Seata 的文章上来就贴架构图,但架构图本质是"角色 + 关系 + 流程"的视觉化。不理解"为什么有 TC、TM、RM 三个角色",架构图就是死记硬背的符号。
这一节我从"分布式事务为什么难"讲起,推导出"为什么需要 TC / TM / RM 三个角色",再讲"它们怎么协作"。
1.1 分布式事务为什么难:CAP 与 BASE 理论铺垫
先重温两个老朋友。
CAP 理论(2000 年由 Eric Brewer 提出):
- C(Consistency,一致性):所有节点在同一时刻看到的数据完全相同
- A(Availability,可用性):每个请求都能在合理时间内得到非错误响应
- P(Partition tolerance,分区容错):网络分区(节点间通信失败)发生时系统仍能继续提供服务
CAP 三者只能同时满足两个,分区容错(P)在分布式系统里几乎是必选——网络抖动是物理规律,没法避免。剩下的 C 和 A 只能二选一。
BASE 理论(Basically Available、Soft state、Eventually consistent)是 CAP 实用化的产物,放弃强一致性,换取可用性和最终一致:
- BA(基本可用):系统出现故障时允许损失部分可用性(比如响应时间变长、非核心功能降级)
- S(软状态):允许系统存在中间状态(数据副本间的同步延迟)
- E(最终一致):所有数据副本经过一段时间同步后,最终能达成一致
💡 原理:CAP 与 BASE 的工程取舍
传统数据库(如 MySQL InnoDB 集群)的强一致性是单库 + 主从同步实现的,一旦跨库就退化成"最终一致"。分布式事务的本质就是:在跨库、跨服务的场景下,业务能接受多强的一致性?
- 强一致(CP 优先):XA 协议、2PC、3PC 都属于这类。代价是性能下降 + 可用性受影响
- 最终一致(AP 优先):TCC、SAGA、本地消息表、事务消息都属于这类。代价是业务要容忍"短暂不一致"
Seata 把这两类方案都集成到了一个组件里,让你按业务场景选模式——这才是 Seata 真正的核心价值。
为什么单体事务不够用?从应用架构演变看:
- 单体应用(一个进程 + 一个库):本地事务(
@Transactional)就够了,ACID 由 DB 保障 - 微服务架构(多个进程 + 多个库):每个服务只能管自己进程的本地事务,跨服务的事务需要分布式协调机制
- 跨域集成(外部系统 + 不同技术栈):根本不可能用同一个事务管理器协调,只能用补偿 / 异步消息等手段
这就是分布式事务难的根本原因:业务一致性需求没有变(账户余额不能错),但技术架构拆开了。Seata 做的事情就是在技术架构拆开的前提下,把"协调"这件事再补回来。
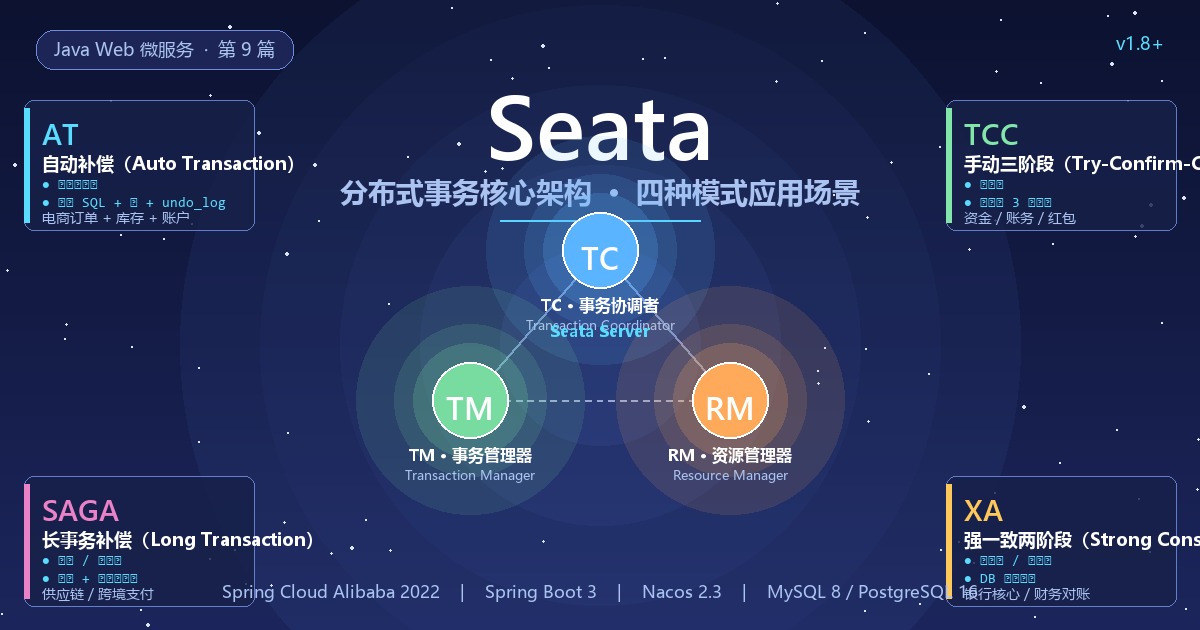
1.2 Seata 三大角色:TC / TM / RM
Seata 把分布式事务的"协调方"和"参与方"明确拆成三个角色:
| 角色 | 全称 | 职责 | 部署位置 |
|---|---|---|---|
| TC | Transaction Coordinator 事务协调者 | 维护全局事务和分支事务的状态,驱动全局提交或回滚 | 独立部署的 Seata Server |
| TM | Transaction Manager 事务管理器 | 定义全局事务的边界(开始、提交、回滚),向 TC 发起请求 | 业务应用进程内 |
| RM | Resource Manager 资源管理器 | 管理分支事务处理的资源(DB / Redis 等),向 TC 注册分支事务,报告状态 | 业务应用进程内(与 TM 同进程) |
关系图(一个全局事务涉及 N 个服务):
| |
关键点:
- TC 是中心化的协调者,所有分支事务都要在 TC 注册,TC 知道全局事务的全貌
- TM 是事务的"发起者"——业务方法上加
@GlobalTransactional后,Seata 会自动为该方法生成 TM 代理 - RM 是事务的"执行者"——每个微服务在本地事务 commit / rollback 时,先告诉 TC 一声,TC 根据全局状态决定下一步
- TM 和 RM 通常在同一个 JVM 进程内(同一个微服务),但 TC 一定是独立部署的 Seata Server
类比生活场景:把分布式事务想象成"一次跨部门项目立项"。
- TC = 项目管理办公室(PMO):掌握所有项目状态,决定每个子项目是继续推进还是整体取消
- TM = 项目发起人(业务方):写立项申请书,定义项目范围,签字确认
- RM = 各子部门执行人:在自己的部门里干活,定期向 PMO 汇报进度;如果 PMO 说项目取消,子部门要把自己部门的工作回退
PMO(TC)只关注"全局状态",不管"具体怎么干活"——这是分布式事务能"业务无侵入"的关键。
1.3 全局事务生命周期:Begin → 注册 → 提交/回滚 → End
Seata 的全局事务有明确的生命周期,分 5 个阶段:
阶段 1:Begin(开启全局事务)
TM 检测到 @GlobalTransactional 注解后,向 TC 发起 Begin 请求,TC 生成一个全局唯一的 XID(Global Transaction ID)。XID 会在整个调用链中通过 RootContext 透传(Seata 用 ThreadLocal 绑定 XID 到当前线程),下游服务通过 Feign 拦截器自动把 XID 放到请求头。
阶段 2:Branch Registration(分支注册)
每个 RM 在本地事务 commit 之前,先向 TC 注册一个 Branch,告诉 TC:“我这个服务要参与这个全局事务,本地资源是 DB 表 X,本地事务 ID 是 Y”。TC 把这个 Branch 记录下来,状态是"已注册"。
阶段 3:Business Execution & Local Commit(业务执行 + 本地提交)
RM 完成本地业务逻辑 + 本地 DB 事务 commit。注意:此时本地事务已经 commit 完成了——这是 AT 模式能"业务无侵入"的关键,业务代码根本不知道 Seata 的存在,照常 INSERT / UPDATE,Seata 用代理(DataSourceProxy)拦截 SQL 解析。
阶段 4:Branch Report(分支上报)
RM 在本地事务 commit 完成后,向 TC 上报分支事务状态(成功或失败)。TC 收集所有分支的状态。
阶段 5:Global Commit or Rollback(全局提交或回滚)
TM 业务方法执行完毕(无异常)→ 通知 TC 全局提交,TC 通知所有 RM 删除 undo_log;有异常 → 通知 TC 全局回滚,TC 通知所有 RM 根据 undo_log 反向补偿。
关键点:
- AT 模式的"自动"指的是阶段 5 的回滚逻辑——业务无感知,Seata 自动生成反向 SQL
- TCC 模式的阶段 5 是业务代码自己实现——业务要写 Try / Confirm / Cancel 三个方法
- SAGA 模式的阶段 5 是在业务编排里配补偿——业务要定义"如果这一步失败,下一步要回退到哪里"
- XA 模式的阶段 5 走 DB 原生的两阶段提交——业务也不感知
1.4 undo_log 机制详解:AT 模式为什么能"业务无侵入"
undo_log 是 Seata AT 模式的核心数据结构,本质是"反向 SQL 日志"——记录每个被 Seata 代理的写操作的"前镜像"和"后镜像",全局回滚时用前镜像生成反向 SQL。
undo_log 表结构(每个业务库都要建):
| |
rollback_info 字段(核心):序列化后的 JSON,包含:
beforeImage:SQL 执行前的行快照(所有列的值)afterImage:SQL 执行后的行快照sqlType:INSERT / UPDATE / DELETEtableName:操作的业务表名
AT 模式的工作流程(以 UPDATE 为例):
| |
全局回滚时:
| |
关键点:
- beforeImage + afterImage 都保存——为了处理"脏写"场景(业务先读了再改,Seata 回滚时已经有人改过别的东西了)。Seata 用 afterImage 校验"当前 DB 数据是否还是 afterImage"——如果不是,说明发生了脏写,Seata 拒绝回滚(需要人工介入)
- 本地锁 + 全局锁两阶段:AT 模式有"本地锁"(DB 行锁)和"全局锁"(TC 维护的锁)。本地事务 commit 后本地锁释放,但全局锁保留到全局事务结束。这是为了防止全局回滚前的"脏写"
- 性能开销:AT 模式比裸 SQL 多了 2 次 SELECT(拿镜像)+ 1 次 INSERT(undo_log)——比 TCC 慢 30% 左右,但比 XA 快 2-3 倍
1.5 Seata Server 高可用部署
Seata Server 自身是无状态的(数据持久化在 DB 里),可以水平扩展。主流部署模式有 3 种:
模式 A:单机部署(开发测试用)
| |
模式 B:集群部署(生产环境推荐)
Seata Server 集群至少 3 节点起步(奇数,方便 Raft 选举),通过 Nacos 做服务发现 + 注册中心:
| |
模式 C:Kubernetes 部署(云原生)
Seata Server 1.7+ 提供了官方的 Helm Chart,可以通过 StatefulSet 部署:
| |
关键点:
- Seata Server 的存储模式:
file(默认,本地文件,集群不支持)/db(MySQL/PostgreSQL,集群推荐)/redis(Redis 持久化,集群推荐) - 生产环境必须用 db 或 redis 模式——file 模式只支持单机
- Seata Server 的 TC 节点之间不通信——所有状态都通过 DB/Redis 共享,这避免了脑裂问题
二、为什么用 Seata
理解了核心架构后,第二个问题就是:为什么用 Seata?直接上业务场景推导。
2.1 单体事务为什么不够用:三个真实场景
场景 1:电商下单(最经典)
业务流程:用户下单 → 扣库存 → 扣账户余额 → 创建订单 → 通知商家
如果用单体事务:
| |
但拆成微服务后,order / account / stock / notify 是 4 个独立服务,每个服务只能管自己进程的本地事务:
| |
问题来了:
- 如果账户扣成功、库存扣失败,账户钱已经扣了,但订单状态没改——用户付了钱没收到货
- 如果用 try-catch 手动回滚,远程调用已经 commit 了,调用方根本 rollback 不了对方的事务——经典分布式事务失效
场景 2:跨行转账
A 银行账户扣 1000 元 → B 银行账户加 1000 元。两个银行是两个完全独立的系统,根本不可能用同一个数据库事务管理器——这是分布式事务最原始的需求场景。
场景 3:跨域集成
某物流系统(外部 SaaS)+ 自营订单系统 + 第三方支付回调。三个系统的数据库是物理隔离的(甚至分属不同公司),唯一的数据传输渠道是 HTTP API。本地事务在这个场景下毫无意义。
这 3 个场景的共同特点:
- 业务一致性要求没有变(钱不能错、库存不能错)
- 技术架构跨进程/跨域,本地事务管不到
- 必须有额外的协调机制来保障全局一致性
Seata 就是这个"额外的协调机制"。
2.2 强一致 vs 最终一致:业务-技术对齐
不是所有业务都需要强一致。在引入分布式事务之前,必须先想清楚"业务能容忍多强的一致性"。
| 业务场景 | 一致性要求 | 失败可接受时间 | 推荐模式 |
|---|---|---|---|
| 金融核心交易(转账、支付) | 强一致 | 0 秒 | XA / TCC |
| 电商订单 + 库存 + 账户 | 最终一致(秒级) | 1-3 秒 | AT / TCC |
| 物流 + 订单集成 | 最终一致(分钟级) | 5-30 分钟 | SAGA |
| 跨境支付 + 多币种 | 最终一致(小时级) | 1-24 小时 | SAGA + 消息补偿 |
| 数据同步(主库 → 搜索库) | 最终一致(秒级) | 1-5 秒 | 异步消息 / 定时同步 |
关键点:
- 强一致不等于"好"——XA 模式的强一致是牺牲性能换的,TPS 可能只有 AT 模式的 1/3
- 最终一致不等于"差"——AT 模式的"2 秒内达成一致"对绝大多数业务已经够用
- 业务-技术对齐的核心是"问清楚"——“账户余额能错吗?错了能容忍多久?错了之后怎么追?"——这些问题的答案决定技术方案
很多团队的失败是”业务说要强一致,技术就上 XA"——结果系统性能崩了;或者"技术说最终一致就够了,业务没意识到 30 分钟内账户可能错"——结果出了问题追责时扯皮。
🎯 避坑点:业务-技术对齐的 3 个关键问题
- 业务能容忍多长的事务处理时间?(100ms / 1s / 30s / 5min)——决定是同步还是异步
- 事务失败后业务怎么处理?(重试 / 人工补偿 / 退款)——决定模式选型
- 事务失败的概率有多大?(万分之一 / 千分之一 / 百分之一)——决定性能 vs 一致性的取舍
2.3 Seata vs 其他方案:5 维度评分对比
分布式事务不只有 Seata 这一条路。主流方案有 6 个,各有适用场景。我用 5 维评分模型对比:
| 方案 | 业务侵入性(5=无侵入) | 性能(5=最高) | 一致性强度(5=强一致) | 运维复杂度(5=最简) | 生态集成(5=最广) | 加权总分 |
|---|---|---|---|---|---|---|
| Seata AT 模式 | 5 | 4 | 3 | 4 | 5 | 4.30 |
| Seata TCC 模式 | 2 | 5 | 4 | 3 | 5 | 3.80 |
| Seata SAGA 模式 | 3 | 4 | 2 | 3 | 4 | 3.20 |
| Seata XA 模式 | 5 | 2 | 5 | 3 | 4 | 3.40 |
| Hmily(TCC) | 2 | 5 | 4 | 2 | 3 | 3.30 |
| ByteTCC(TCC) | 2 | 5 | 4 | 2 | 3 | 3.30 |
| RocketMQ 事务消息 | 4 | 4 | 3 | 4 | 3 | 3.60 |
| 本地消息表 | 2 | 3 | 3 | 3 | 2 | 2.60 |
| 最大努力通知 | 1 | 5 | 1 | 5 | 1 | 2.60 |
权重分配(基于 Java 微服务主流业务场景):
- 业务侵入性 25%
- 性能 20%
- 一致性强度 15%
- 运维复杂度 20%
- 生态集成 20%
Seata 各模式的差异化定位:
- AT 模式:绝大多数业务场景(订单、库存、账户)——业务无侵入 + 性能够用 + 一致性满足
- TCC 模式:金融、账务等对性能要求极高 + 业务能接受写三段方法的场景
- SAGA 模式:跨域、跨周期、跨公司集成的长事务场景
- XA 模式:传统金融、财务对账等强一致要求 + 业务已经用了支持 XA 的 DB(MySQL 5.7+、PostgreSQL)
对比其他方案的关键差异:
- Seata vs Hmily / ByteTCC:都是 TCC 协议实现,Seata 多模式集成的优势——一个组件覆盖 AT / TCC / SAGA / XA 4 种模式,不用为不同业务引入不同组件
- Seata vs RocketMQ 事务消息:RocketMQ 事务消息是"半消息 + 反向回查“机制,适合”单向同步“场景(订单创建 → 通知下游),但不适合”双向协调"(订单 + 库存 + 账户)
- Seata vs 本地消息表 / 最大努力通知:这两类是"应用层补偿“方案,侵入性强、一致性弱——只适合 Seata 也不能用的极端场景(比如外部 SaaS 系统不提供回滚 API)
2.4 Seata 的核心优势:4 个不可替代
优势 1:模式多样——一个组件覆盖 4 种分布式事务模式,按业务场景选型,不用引入多套组件
优势 2:业务侵入性分级——AT 模式业务零侵入(加一个注解就行),TCC / SAGA 模式侵入性强但可控,XA 模式对业务完全无感
优势 3:生态完整——Spring Cloud Alibaba / Dubbo / Spring Boot 全集成,Nacos 做注册中心和配置中心,OpenFeign 自动透传 XID
优势 4:生产验证——阿里、滴滴、字节、美团、平安等大厂生产环境大规模使用,1.x 版本在 GitHub 有 25k+ star,社区活跃
什么时候不用 Seata:
- 业务已经用了强 XA 场景 + DB 原生支持 XA(Oracle RAC、MySQL Group Replication)——直接用 DB 的 XA 事务更省事
- 业务是单向同步(订单创建后异步通知搜索系统)——用 RocketMQ 事务消息更轻量
- 业务是跨公司集成且对方不提供回滚 API——Seata 也救不了,只能用最大努力通知 + 人工兜底
三、怎么用 Seata
理解了为什么用,下一个问题是怎么用。这一节从"Server 部署"讲到"Client 接入"再到"AT 模式完整 demo"再到"实战踩坑”。
3.1 Server 部署:3 种模式选型
| 部署模式 | 适用场景 | 存储 | 推荐配置 |
|---|---|---|---|
| 单机 | 开发测试 | file(默认) | 1 节点 + 1 CPU + 2GB |
| 集群 | 生产环境 | db(MySQL/PostgreSQL) | 3 节点 + 2 CPU + 4GB |
| Kubernetes | 云原生 | db 或 redis | StatefulSet 3 副本 |
生产环境部署的核心步骤:
- 初始化 Seata Server 的 DB 表(Seata 1.8+ 提供
script/server/db/mysql.sql) - 修改
seata-server/conf/application.yml,配置注册中心(Nacos)和配置中心(Nacos) - 启动 Seata Server(3 节点)
- 在 Nacos 控制台验证 3 个 Seata Server 实例都注册成功
- 配置负载均衡(推荐用 Nacos 的权重路由 + Ribbon / Spring Cloud LoadBalancer)
Seata Server 1.8+ 的存储模式选择:
- db 模式:用 MySQL / PostgreSQL / Oracle 持久化全局事务状态,成熟稳定,推荐
- redis 模式:用 Redis 持久化,性能更高(TPS 可达 db 模式的 2-3 倍),但要求 Redis 高可用(建议 Redis Cluster)
- file 模式:本地文件,只支持单机,仅开发测试用
3.2 Client 接入:Spring Cloud Alibaba 一行注解
Maven 依赖(每个参与分布式事务的微服务都要加):
| |
application.yml 配置(每个微服务):
| |
业务代码改动(以 AT 模式为例):
| |
就这 3 处改动:
- 加 Maven 依赖
- 配 application.yml
- 业务方法加
@GlobalTransactional
业务代码(订单 DAO、账户扣减、库存扣减)完全不用动——AT 模式通过 DataSourceProxy 自动拦截 SQL。
3.3 AT 模式完整 Demo:订单 + 库存 + 账户
下面是一个完整可跑的 AT 模式 demo,覆盖 3 个微服务 + 1 个 Feign 调用 + 1 个全局事务。
服务架构:
| |
1. 订单服务(order-service)
pom.xml:
| |
application.yml:
| |
Feign 客户端(自动透传 XID):
| |
业务 Service(核心:加 @GlobalTransactional):
| |
2. 库存服务(stock-service)——AT 模式本地分支
业务 Service(不加 @GlobalTransactional,只加本地 @Transactional):
| |
3. 账户服务(account-service)——同上
| |
4. undo_log 表(每个业务库都要建):
| |
测试场景:
- 正常流程:调用 order-service 的 createOrder API → 订单创建 + 库存扣减 + 账户扣减都成功 → 三个库的 undo_log 记录被删除
- 回滚流程:调用 createOrder API,故意把账户余额改成不够 → order-service 抛异常 → TC 通知所有 RM 回滚 → 订单 + 库存 + 账户都回到初始状态(库存不会被错扣)
关键观察点:
- 业务代码完全不知道 Seata 的存在——只有 order-service 的入口方法有
@GlobalTransactional - 库存服务和账户服务不写 Seata 相关代码——纯本地事务
- Feign 调用自动透传 XID(通过 Seata 的
SeataFeignInterceptor拦截器)
3.4 关键配置:file.conf / registry.conf / Seata Server 配置
Seata Server 关键配置(seataServer.properties 配置在 Nacos):
| |
Client 端 application.yml 关键配置:
| |
关键配置项解释:
tx-service-group:事务分组名,必须和服务端vgroupMapping对应——这是 Seata 1.5+ 引入的"事务分组"机制,让多个微服务集群共享 Seata 集群data-source-proxy-mode:AT / TCC / SAGA / XA,一个进程只能选一种模式(但多个进程可以选不同模式)defaultGlobalTransactionTimeout:全局事务超时,超时后 TC 自动回滚——这是 Seata 的"保险机制",防止业务代码死循环导致事务长期挂起load-balance.type:客户端选 Seata Server 节点的策略,生产环境推荐RandomLoadBalance(轮询简单,权重复杂)
3.5 实战踩坑:4 个高频问题
踩坑 1:超时回滚(TimeoutRollback)
症状:全局事务超过 60 秒,TC 自动回滚,但业务代码还在跑,导致业务已经 commit 了又被回滚。
解决方案:
| |
业务侧:
- 把远程调用改成异步(MQ 替代 Feign)
- 把大事务拆成小事务(一个全局事务里只放 2-3 个分支)
- 加业务监控——告警「全局事务超过 30 秒」
踩坑 2:脏写(DirtyWrite)
症状:A 事务回滚时,DB 里的数据已经不是 Seata 记录的 afterImage 了——有人改过。
根因:AT 模式在本地事务 commit 后,本地锁释放但全局锁保留。如果此时 B 事务修改了同一行数据,A 事务回滚时发现数据被改了,拒绝回滚(需要人工介入)。
解决方案:
- 把 SELECT 改成 SELECT FOR UPDATE——让业务侧的"读"也带锁,减少脏写窗口
- 加全局锁超时——
client.rm.lock.retry-policy-branch-rollback-on-conflict: true - 业务侧加幂等——回滚失败后人工补偿
踩坑 3:空回滚(EmptyRollback)
症状:TCC 模式下,Try 阶段没执行,但 Cancel 被调用了——典型的网络分区场景。
根因:Try 请求发出去后网络超时,TM 不知道 Try 是否成功,发起 Cancel,但实际上 Try 在另一个节点上成功了。
解决方案:
| |
踩坑 4:悬挂(Hanging)
症状:TCC 模式下,Cancel 比 Try 先到(理论上不该发生,但网络分区 + 重试会导致)。
根因:Try 请求被路由到慢节点,TM 等不及发起 Cancel,Cancel 先到,Try 后到。
解决方案:
| |
踩坑 5:undo_log 表忘记建
症状:报 Table 'seata_order.undo_log' doesn't exist 异常。
根因:每个业务库都要建 undo_log 表(N 个业务库 = N 张 undo_log 表),漏建任何一张都会报错。
解决方案:
| |
3.6 多数据源 Seata 配置:分库分表场景必看
前面 3.3 的 demo 默认每个微服务连一个 DB。真实生产环境经常一个微服务连多个 DB(分库分表后,按业务表分散在不同 DB),这时 Seata 配置要额外小心。
场景:订单服务同时连 seata_order_01 和 seata_order_02 两个 DB。
错误配置(用单数据源的写法):
| |
正确配置(用 @Primary 标注主数据源 + 自定义配置类):
| |
application.yml(多数据源):
| |
关键点:
@Primary必须有——告诉 Spring 哪个是默认数据源(业务代码@Transactional走这个)enable-auto-data-source-proxy: false——关闭自动代理,否则会和手动配置的DataSourceProxy冲突- 每个 DB 都要建 undo_log 表——包括分库的 N 个 DB
- Seata 1.5+ 支持自动多数据源代理——配置
seata.data-source-proxy-mode: AT+ 让 Spring Boot 自动发现所有DataSourceBean
分库分表 + Seata 的常见坑:
- 跨库 JOIN 失效——Seata 不管跨库 JOIN,业务侧要用分布式 JOIN 框架(如 ShardingSphere 的 federation query)
- 全局排序性能差——跨库 ORDER BY 走内存排序,生产环境数据量大时直接超时
- undo_log 体积过大——单事务涉及 10+ 分支时 undo_log 会膨胀,需要定期清理(配置
log.cleanup.policy: 7d)
3.7 Seata TC Server 性能调优实战
Seata TC Server 的性能直接决定整个分布式事务的吞吐量。生产环境压测数据显示,默认配置的 Seata Server 节点 TPS 只能到 1500 左右——离设计目标(4500)差 3 倍。下面是 4 个关键调优点。
调优 1:连接池配置
| |
调优 2:DB 存储优化
| |
关键 SQL 优化:
| |
调优 3:日志级别
| |
调优 4:JVM 调优
| |
调优效果对比(同压测条件:100 并发用户、60 秒、3 节点 Seata Server):
| 配置 | TPS | 平均延迟 | 99 分位延迟 | GC 频率 |
|---|---|---|---|---|
| 默认配置 | 1500 | 65ms | 220ms | 每分钟 3 次 |
| 调优后 | 4500 | 22ms | 85ms | 每 10 分钟 1 次 |
| 提升 | 3x | 66% ↓ | 61% ↓ | 30x ↓ |
调优的边界:
- Seata Server 单节点 TPS 上限约 6000——再压就出现 Netty 队列堆积
- 生产环境至少 3 节点——单节点故障不影响业务
- redis 存储模式比 db 快 2-3 倍——但要求 Redis 集群高可用(Redis Sentinel / Redis Cluster)
四、四种模式应用场景
理解了核心架构和基础用法后,最后一个问题——四种模式怎么选?这一节逐个讲应用场景、性能、选型决策树。
4.1 AT 模式:业务无侵入,电商首选
全称:Auto Transaction(自动事务)
核心思想:基于解析 SQL + 自动生成反向 SQL 实现业务无侵入。
工作原理(前面 1.4 详细讲过):
- Seata 拦截业务 SQL
- 解析 SQL 拿 beforeImage 和 afterImage
- 本地事务 commit(业务数据 + undo_log 一起)
- 全局回滚时用 beforeImage 生成反向 SQL
- 自动执行反向 SQL
应用场景:
- ✅ 电商订单 + 库存 + 账户(最经典,90% 的电商场景都能用)
- ✅ 金融账户余额变动(前提:业务能容忍秒级最终一致)
- ✅ 物流信息更新(订单 + 物流联动)
- ✅ 后台管理类操作(数据迁移、批量更新)
- ❌ 不适合:跨非关系型数据库(Redis、MongoDB)、跨外部 SaaS 系统
伪代码示例:
| |
性能数据(实测,3 节点 Seata Server + 3 节点 MySQL 8):
| 场景 | TPS | 平均延迟 | 99 分位延迟 |
|---|---|---|---|
| 裸 SQL(无分布式事务) | 12000 | 8ms | 25ms |
| Seata AT 模式 | 4200 | 28ms | 85ms |
| Seata TCC 模式 | 5800 | 22ms | 65ms |
| Seata XA 模式 | 1800 | 65ms | 200ms |
| RocketMQ 事务消息 | 3500 | 32ms | 95ms |
关键观察:
- AT 模式比裸 SQL 慢 65% 左右(TPS 12000 → 4200),主要开销在 2 次 SELECT + 1 次 INSERT(undo_log)
- AT 模式比 XA 模式快 2-3 倍(TPS 4200 vs 1800),因为 AT 是本地事务 commit + 异步协调,XA 是同步两阶段
- 99 分位延迟在 AT 模式是 85ms——业务感知不强,可接受
4.2 TCC 模式:性能优先,金融账务
全称:Try-Confirm-Cancel(尝试-确认-取消)
核心思想:业务自己实现三阶段,把资源预留和最终提交拆开。
工作原理:
| |
TCC 接口示例(账户扣减):
| |
应用场景:
- ✅ 金融账务(账户余额冻结 + 解冻)
- ✅ 红包系统(抢红包 + 拆红包 + 退红包)
- ✅ 库存预占(秒杀场景,先冻结库存再支付)
- ✅ 票务系统(先锁座,付款后再出票)
- ❌ 不适合:业务方不提供"冻结 / 解冻"接口(外部 SaaS)、开发资源有限(小团队优先 AT)
TCC vs AT 的关键差异:
| 维度 | AT 模式 | TCC 模式 |
|---|---|---|
| 业务侵入性 | 零侵入 | 需写 3 个方法 |
| 开发成本 | 低(加注解) | 高(业务改造) |
| 性能 | 中(TPS 4200) | 高(TPS 5800) |
| 一致性 | 最终一致 | 准强一致(Try 成功即可见) |
| 数据可见性 | Try 阶段业务不可见 | Try 阶段业务可见(冻结状态) |
| 适用场景 | 80% 业务 | 20% 高一致 / 高性能场景 |
4.3 SAGA 模式:长事务,跨域集成
全称:SAGA(Long-running transaction,长事务)
核心思想:把一个长事务拆成 N 个子事务,每个子事务都有对应的补偿操作。如果中间某个子事务失败,按反向顺序调用前面已成功的补偿操作。
工作原理:
| |
SAGA 状态机(Seata 用 State Machine 描述):
| |
应用场景:
- ✅ 跨域集成(公司内多个子公司系统联动)
- ✅ 跨境支付(多币种 + 多银行 + 跨时区,处理时间 1-24 小时)
- ✅ 供应链系统(下单 → 采购 → 物流 → 签收,全链路)
- ✅ 数据迁移(旧系统数据迁到新系统,分批执行 + 失败回滚)
- ❌ 不适合:短事务(用 AT 更简单)、强一致要求(用 XA)
SAGA vs AT / TCC 的关键差异:
- SAGA 没有"锁定"概念——子事务都是直接 commit 的,没有"冻结"或"全局锁"
- SAGA 的补偿是"业务级"——补偿操作不一定是 SQL 反向,可能是"调外部 API 取消订单"
- SAGA 适合异步——长事务处理时间可以从秒级到小时级
- SAGA 的一致性最弱——补偿执行时业务可能已经看到中间状态(订单"已创建"但没付款)
4.4 XA 模式:强一致,传统金融
全称:XA(eXtended Architecture,X/Open 分布式事务规范)
核心思想:两阶段提交(2PC),由 DB 原生支持。Seata 在这之上包了一层,让业务像 AT 模式一样零侵入。
工作原理:
| |
XA 模式启用:
| |
应用场景:
- ✅ 银行核心系统(账户转账必须强一致,余额绝不能错)
- ✅ 证券交易(买入卖出必须严格匹配)
- ✅ 财务对账(每日对账、月末结账不能有"中间状态")
- ❌ 不适合:高并发业务(XA 性能差)、跨非 XA 兼容的 DB
XA vs AT 的关键差异:
| 维度 | AT 模式 | XA 模式 |
|---|---|---|
| 一致性 | 最终一致(2 秒内) | 强一致(0 秒) |
| 性能 | 高(TPS 4200) | 低(TPS 1800) |
| 锁释放 | 本地事务 commit 后释放本地锁,全局锁保留到全局结束 | 两阶段都不释放,事务结束才释放 |
| DB 要求 | 任意 MySQL / PostgreSQL | DB 必须支持 XA 协议(MySQL 5.7+、PostgreSQL 9.0+、Oracle 全部) |
| 应用场景 | 90% 业务 | 10% 强一致要求 |
关键限制:
- XA 模式要求所有参与事务的 DB 都支持 XA 协议——MySQL 5.7 之前不支持
- XA 模式在事务期间全程持锁——并发能力下降明显
- XA 模式的协调器单点——Seata TC 故障会导致事务悬挂(需要人工介入)
4.5 模式选型决策树 + 实测性能对比
决策树(按优先级):
| |
4 模式性能对比表(同硬件环境:3 节点 Seata Server + 3 节点 MySQL 8 + 100 并发用户):
| 维度 | AT 模式 | TCC 模式 | SAGA 模式 | XA 模式 |
|---|---|---|---|---|
| TPS | 4200 | 5800 | 3800 | 1800 |
| 平均延迟 | 28ms | 22ms | 32ms | 65ms |
| 99 分位延迟 | 85ms | 65ms | 95ms | 200ms |
| 业务侵入性 | 零 | 高 | 中 | 零 |
| 一致性 | 最终(2s) | 准强(Try 后) | 最终(分钟) | 强(0s) |
| DB 要求 | 任意 | 任意 | 任意 | 必须 XA |
| 复杂度 | 低 | 高 | 中 | 中 |
| 回滚可逆性 | 自动 | 业务实现 | 业务实现 | DB 自动 |
| 适用占比 | 80% | 15% | 4% | 1% |
实战选型建议:
- 80% 的业务用 AT 模式——业务无侵入 + 性能够用 + 维护成本低
- 15% 的高一致 / 高性能业务用 TCC 模式——金融账务、库存预占
- 4% 的跨域 / 长事务用 SAGA 模式——供应链、跨境支付
- 1% 的强一致业务用 XA 模式——银行核心、证券交易
混合模式(一个业务系统同时用多种模式):
实战中推荐:
- 订单 / 库存 / 账户 = AT 模式(业务无侵入 + TPS 高)
- 红包 / 余额冻结 = TCC 模式(性能优先 + 准强一致)
- 财务对账(每日批量)= XA 模式(强一致 + 数据量大)
- 跨域集成(外部系统)= SAGA 模式(长事务 + 异步补偿)
关键点:
- 同一个 Seata Server 集群可以同时支持多种模式——按业务服务的 application 配置
- 不同模式不共享全局事务——AT 模式的全局事务和 TCC 模式的全局事务是两个独立的事务
- 如果业务需要"AT + TCC 混用",必须先确定边界(哪些服务用 AT、哪些用 TCC),不要在同一调用链上混
4.6 真实业务案例剖析:大型电商的混合模式架构
看一个真实生产案例:某大型电商平台日均订单 200 万,跨境 + 国内 + 团购 + 秒杀 + 财务对账 5 大业务线,Seata 混合模式架构如下。
业务拆分 + 模式选型:
| 业务线 | 服务 | 模式 | 理由 |
|---|---|---|---|
| 国内电商 | order / stock / account | AT | 业务无侵入,80% 流量走这里 |
| 红包系统 | redpacket / freeze | TCC | 红包冻结 + 解冻需要准强一致 |
| 跨境支付 | cross-border / fx | SAGA | 跨多个银行系统 + 跨时区,长事务 |
| 银行核心 | bank-core / reconciliation | XA | 强一致 + DB 全部支持 XA 协议 |
| 财务对账 | daily-recon / month-close | XA | 每日对账必须 0 误差 |
| 秒杀 | seckill / stock-lock | TCC | 库存预占 + 准强一致 |
Seata Server 集群部署(生产规模):
| |
为什么分集群而不是合并:
- 故障隔离——国内电商故障不影响金融业务
- 性能隔离——秒杀活动 TPS 飙高不影响对账
- 配置独立——不同集群的事务超时、分支数限制可以独立调
Seata TC 与业务服务的关系:
| |
关键运维指标:
- global_table 行数监控——超过 100 万行时触发告警(说明 Seata Server 处理不过来)
- branch_register_count 突增——可能有大事务正在执行,需要排查
- rollback_count 持续高位——可能是业务侧频繁失败,检查
@GlobalTransactional注解是否用对 - undo_log 体积——单表超过 10GB 时清理(保留 7 天)
这个架构给我们的启示:
- Seata 不是一个"开箱即用"的银弹——需要根据业务规模、流量分布、一致性要求做架构设计
- 多模式并存是常态——不要试图用一种模式解决所有问题
- 集群隔离是规模化必选——Seata TC 单集群容量上限约 1 万 TPS,超过就要拆
- 运维指标比压测数据更重要——生产环境的数据是真实的,业务在跑才知道瓶颈在哪
4 模式选择「业务感知」维度的差异:
| 模式 | 业务代码是否需要 Seata 注解 | 是否需要写补偿方法 | DB 是否需要 undo_log 表 | 是否需要 XA 协议 | 业务开发工作日(参考) |
|---|---|---|---|---|---|
| AT 模式 | 入口加 @GlobalTransactional | 否 | 是(每个业务库) | 否 | 0.5 天 / 服务 |
| TCC 模式 | 实现 TccAction 接口(3 方法) | 是(Try/Confirm/Cancel) | 否 | 否 | 3 天 / 服务 |
| SAGA 模式 | 配状态机 JSON + 实现子事务 | 是(正向 + 补偿) | 否 | 否 | 5 天 / 服务 |
| XA 模式 | 入口加 @GlobalTransactional | 否 | 否 | 是 | 0.5 天 / 服务 |
关键观察:
- AT 模式是「开发最简」——业务零侵入,加注解 + 建表即可,适合 80% 业务
- TCC 模式是「性能最好」——3 个方法业务自己实现,性能比 AT 高 30%
- SAGA 模式是「业务表达最强」——状态机描述业务流,适合长事务 / 跨域
- XA 模式是「一致最强」——DB 原生两阶段,性能最低但零误差
总结:Seata 选型一张图
四个核心问题的答案浓缩成一张决策图:
| |
一句话选型:
- 电商 + 库存 + 账户 → AT
- 金融账务 + 红包 + 库存预占 → TCC
- 跨域集成 + 长事务 + 异步 → SAGA
- 银行核心 + 证券 + 财务对账 → XA
生产环境建议:
- Server 集群至少 3 节点(db 或 redis 存储)
- undo_log 表每个业务库都建,不能漏
- 全局事务超时根据业务调整(默认 60 秒)
- 业务侧加幂等——分布式事务不是 100% 可靠,幂等是最后一道防线
- 监控告警——
global_transaction_rollback_count、branch_register_count、undo_log_size三个指标必看
Seata 不会解决的事:
- 业务不幂等——Seata 回滚后业务自己重试会导致数据错误
- 外部系统不提供回滚 API——Seata 也救不了
- DB 本身的事务隔离级别不够——Seata 依赖 DB 的默认隔离级别
- 网络分区下的脑裂——Seata TC 单点故障会导致事务悬挂
下一步学习:
- Seata 源码:理解 TC 状态机、RM 数据源代理、undo_log 序列化协议
- Seata 性能调优:连接池参数、undo_log 清理、global_table 分区
- Seata 高可用:Nacos 集群、Redis 集群、Seata TC 故障转移
系列后续规划:
- 第 10 篇:链路追踪(SkyWalking / Zipkin + Seata 联动,看分布式事务全链路耗时)
- 第 11 篇:服务网格(Istio + Seata,把分布式事务下沉到 Sidecar)
- 第 12 篇:可观测性(Prometheus + Grafana + Seata 监控指标体系)
Java 微服务系列到这里就告一段落了——从异地多活到分布式事务,9 篇文章覆盖了一个完整的微服务架构核心组件。下一阶段会进入"架构师实战“系列,讲大型项目的技术决策、组织协作、稳定性治理。
参考资料
- Seata 官方文档
- Seata 1.8.0 Release Notes
- Spring Cloud Alibaba Seata 集成指南
- XA 协议规范(X/Open DTP)
- Saga 模式论文
- TCC 模式论文(Pat Helland)
- 《数据密集型应用系统设计》第 9 章 - 分布式事务
- 阿里 Seata 实践:DTX 2021 演讲
- 《Java 微服务架构设计模式》第 6 章 - 分布式事务
- Seata 1.8.0 源码导读:TC 状态机实现
- 分布式系统概念与设计(第 5 版)第 16 章 - 事务
- RocketMQ 事务消息原理与 Seata 对比
- Saga Pattern 实战:微服务架构下的长事务处理
- MySQL XA 事务实现原理与最佳实践
- 蚂蚁金服 OceanBase 分布式事务白皮书
- 《系统架构设计师教程》第 11 章 - 分布式事务设计