Java Web 微服务系列 · 第 2 篇 · 流量调度 阅读时长:约 38 分钟 本文写于 2026 年 6 月 前置阅读:《异地多活:Java Web 微服务的高可用终极形态》(系列第 1 篇)
引子:流量调度是异地多活的"前哨班"
系列第 1 篇《异地多活:Java Web 微服务的高可用终极形态》我们讲清楚了"业务单元化 + 存储双向同步 + 流量层分片"是异地多活的三大支柱,并画了完整的架构图。但那张图里最顶上的"用户请求"到"机房入口"之间,其实藏着一层很多人会忽略的细节——流量调度层。
本文约定:本篇是系列第 2 篇,专攻"流量调度"这一层。读完你会知道:阿里、美团、字节这些大厂的异地多活架构,流量入口不是单一组件,而是"公网 LB → LVS → Nginx → 应用网关“四级串联的"前哨班”。
我们用一个真实场景开场:
2021 年某电商双 11 零点,入口流量是平时的 30 倍。第一道前哨——DNS 解析——把用户路由到最近的 CDN 边缘节点,扛掉了 80% 的静态请求。剩下 20% 的动态请求进入机房后,第二道前哨——LVS——在内核态做四层负载,把 50 万 QPS 均匀分给后方的 8 台 Nginx。第三道前哨——Nginx——做七层路由(按 Host 头、URL 路径分流到不同微服务)。三层前哨环环相扣,任意一层挂掉,下一层都能自动承接。
这就是流量调度的全部奥秘——冗余 + 分流 + 自动故障切换。本篇按"单机 → 双机 → 集群 → 跨城"的演进顺序,把这条前哨班完整搭一遍。实操部分会给你完整可复制粘贴的命令清单,2 台虚拟机就能跑通整套 LVS + Keepalived + Nginx 链路。
一、流量调度的本质:4 层 / 7 层 / 高可用
异地多活架构里,“流量调度"听起来抽象,本质就是回答三个问题:
- 用户的请求先到谁?(入口选择)
- 到达入口后怎么分给后端?(负载均衡)
- 后端某台机器挂了怎么办?(高可用)
1.1 三层位置:流量调度在异地多活中的定位
先把流量调度放到异地多活的整体架构里看:
这张图里,流量调度对应"公网 LB → LVS → Nginx"这三层。本篇只讲这三层(DNS / CDN 属于另一条线,Spring Cloud Gateway 是微服务层的网关,留给系列第 3 篇)。
1.2 4 层 vs 7 层:性能与灵活性的权衡
| 维度 | 4 层(L4) | 7 层(L7) |
|---|---|---|
| 工作层级 | 传输层(TCP/UDP) | 应用层(HTTP/HTTPS) |
| 看的信息 | 源 IP、目标 IP、端口 | 全部 HTTP 头、URL、Cookie、Body |
| 典型代表 | LVS、Haproxy(四层模式)、AWS NLB | Nginx、Tengine、Envoy、Traefik |
| 性能 | 几十万 QPS(内核态) | 1-5 万 QPS(用户态) |
| 加密终结 | 不终结 TLS | 可终结 TLS(看 https 证书) |
| 路由能力 | 仅 IP/端口级 | Host / URL / Header / Cookie 级 |
| 典型用途 | 入口抗量、跨机房流量分发 | 域名路由、灰度、A/B 测试 |
💡 原理:4 层为什么快?
4 层负载工作在 Linux 内核协议栈的
IPVS(IP Virtual Server)层,数据包在内核态就被转发了,不再上送用户态。7 层负载必须把整个 TCP 流接完、解析 HTTP 头,才能决定转发给谁,至少多两次上下文切换 + 一次内存拷贝。这就是 LVS 能扛 50 万 QPS 而 Nginx 只能扛 1-5 万 QPS 的根本原因。不是 LVS 算法多牛,是它根本不离开内核。
1.3 流量调度的核心目标
不论用 Nginx 还是 LVS,流量调度的目标都只有 3 个:
- 均匀:把请求均匀分给后端机器,避免热点
- 健康:自动剔除故障机器,恢复后自动加回
- 切换:主节点故障时,备用节点秒级接管(Keepalived 负责)
这 3 个目标对应负载均衡算法、健康检查、故障转移三个具体机制。后文逐个讲。
1.4 4 层 vs 7 层:一场持续 20 年的争论
从 2002 年 Nginx 诞生起,“4 层够用还是必须 7 层"就是架构圈反复争论的话题。本质上是性能 vs 灵活性的取舍:
4 层派的论据:
- 内核态转发,单包转发延迟 < 10 微秒
- 看不到应用层数据 = 更安全(攻击面小)
- 协议无关,MySQL / Redis / MQTT / 游戏 TCP 都能代理
7 层派的论据:
- 能看 HTTP 头,按 URL 路由 / 按 Cookie 灰度 是刚需
- TLS 终结在反代层,后端明文 HTTP 性能高 3 倍
- 业务错误码(如 5xx)能被反代识别,故障定位更准
实战结论(业界 20 年沉淀的共识):
- 入口第一跳用 4 层(LVS)抗量
- 入口第二跳用 7 层(Nginx)做业务路由
- 不要"用 7 层做 4 层的事”——比如用 Nginx 做 MySQL 代理,性能差 10 倍
- 不要"用 4 层做 7 层的事”——比如想用 LVS 按 URL 路由,做不到
💡 原理:4 层 + 7 层是"串联"不是"二选一"
真正的生产架构是 4 层在前、7 层在后,串联成两层。4 层负责"抗量 + 入口安全",7 层负责"业务路由 + 灰度"。每一层做自己擅长的事,不要试图用一层解决所有问题。
1.5 为什么"切换"比"均衡"更重要?
很多初学者以为负载均衡的核心是"算法选哪个"(轮询、最少连接、一致性哈希……)。错。真正决定系统可用性的是故障切换速度:
- 算法选错:后端 3 台机器变成 2 台在干活,QPS 降 33%,用户可能没感知
- 切换太慢:后端 1 台机器挂了,10 秒内没人接管,所有打到这台机器的请求都失败,用户感知强烈
所以本文会用大量篇幅讲 Keepalived 和 LVS 的故障切换——这才是流量调度的"命门"。
二、单机 Nginx:1 万 QPS 的边界
2.1 Nginx 凭什么成为"事实标准"
Nginx 2002 年由俄罗斯工程师 Igor Sysoev 写出来,最初是为了解决 C10K 问题——单机如何同时处理 1 万个并发连接。采用事件驱动的异步非阻塞模型,用 1 个 worker 进程就能扛几千个连接。
核心设计:
- Master-Worker 模型:1 个 master 进程负责管理,N 个 worker 进程负责处理请求(
worker_processes auto默认等于 CPU 核数) - 事件循环:每个 worker 用 epoll(Linux)/ kqueue(BSD)系统调用,单线程处理所有连接
- 内存占用低:每个连接约 2-4 KB,而 Apache 一个进程一个连接要 1-2 MB
2.2 反向代理的最简配置
Nginx 做反向代理的最核心 3 段配置:
| |
3 段配置的职责:
upstream:声明后端服务器列表 + 负载均衡参数server { listen 443 ssl }:终结 HTTPSproxy_pass http://backend:把请求转给 upstream,这是反向代理的"反"字所在——客户端只看到 Nginx,看不到后端
2.3 性能调优三件套:worker / connection / keepalive
Nginx 默认配置偏保守,生产环境必须调 3 个参数:
| |
3 个核心参数的内在逻辑:
| 参数 | 含义 | 调优依据 |
|---|---|---|
worker_processes | worker 进程数 | 等于 CPU 核数;过多导致上下文切换开销 |
worker_connections | 每 worker 最大连接 | 受 worker_rlimit_nofile 限制;理论最大并发 = workers × connections |
keepalive | 与后端保持的长连接数 | 关键! 默认 0(每次新建 TCP 连接)会导致 TIME_WAIT 飙升 |
🎯 避坑点:keepalive 默认 0 的隐形坑
Nginx 默认与后端不保持长连接(
upstream里没有keepalive指令时)。每个 HTTP 请求都要 3 次握手 + 4 次挥手,并发一大就出现:
- TIME_WAIT 状态连接数飙升(端口耗尽)
- 后端 CPU 飙升(accept 新连接 + 关闭旧连接的开销)
生产配置必加
keepalive 32(与每台后端保持 32 个长连接池)。这是 Nginx 性能调优的"第一性原则"。
2.4 单机瓶颈:1 万 QPS 的天花板
调优到极致后,单机 Nginx 的上限大约:
- 静态文件:5-10 万 QPS(取决于磁盘 IO / CDN 协同)
- 动态反代:1-3 万 QPS(受后端应用限制)
- TLS 终结:5-8 千 QPS(CPU 密集,受证书算法影响)
单机撑不住怎么办? 两条路:
| 路径 | 适用场景 | 代价 |
|---|---|---|
| 垂直扩展(换更牛机器) | 业务量增长 50% 以内 | 边际成本急剧上升,10 万 QPS 后失效 |
| 水平扩展(多加几台 Nginx) | 长期增长 | 需要在前置加一层负载均衡——这就引出了 Keepalived 和 LVS |
📌 实践:什么时候单机 Nginx 就够了?
经验值:
- 日活 < 10 万:单机 Nginx 足够
- 日活 10-100 万:Nginx + Keepalived 双机
- 日活 > 100 万 或 强 SLA 4 个 9:LVS + Keepalived + Nginx 三层塔
但强可用性要求的系统(金融、交易、支付),即使日活不高也要 LVS 三层塔——因为单机 Nginx 挂了就全挂,没有容错。
2.5 epoll 详解:Nginx 高并发的"内功心法"
Nginx 能扛高并发,核心在于它使用了 epoll(Linux 2.6+ 内核提供的 I/O 多路复用接口)。要理解 epoll 是什么,先看传统模型的瓶颈:
传统 BIO(Blocking I/O)模型:
| |
1 万并发 = 1 万个线程。每个线程默认栈 8 MB,光内存就要 80 GB。上下文切换开销也爆炸。
NIO(Non-blocking I/O)+ epoll 模型:
| |
epoll 的 3 个关键优势:
| 优势 | 含义 |
|---|---|
| 事件驱动 | 只处理"就绪"的连接,未就绪的连接不消耗 CPU |
| O(1) 就绪查询 | 不管 1 万还是 100 万连接,就绪查询都是 O(1) |
| 内核-用户态共享内存 | 通过 mmap 避免每次事件都从内核复制到用户态 |
Nginx 的 worker 进程 = 1 个 epoll 循环。1 个 worker 处理 1 万连接只需几十 MB 内存。这就是 Nginx “小马拉大车"的秘密。
🎯 避坑点:worker 数不是越多越好
常见错误:
worker_processes 32(机器才 8 核)。32 个 worker 抢 8 个 CPU,频繁上下文切换,性能反而下降。正确配置:
worker_processes auto(让 Nginx 自动检测 CPU 核数)。worker 数 = CPU 核数是经验最优值。
三、Nginx + Keepalived:同城双活的"经典双子星”
3.1 为什么需要 Keepalived
单机 Nginx 的"高可用"问题是:Nginx 机器本身挂了怎么办?
用户访问的 IP 是 Nginx 机器的 IP,Nginx 挂了,IP 跟着没了。必须有一个"备用 Nginx"能在主 Nginx 挂掉时接管 IP——这就是 Keepalived 干的事。
Virtual IP(VIP) 是关键:用户访问的 192.168.1.100 不是任何机器的物理 IP,而是一个虚拟 IP,由 Keepalived 在主备机器之间漂移。
3.2 VRRP 协议:VIP 漂移的原理
Keepalived 的核心是 VRRP 协议(Virtual Router Redundancy Protocol,虚拟路由冗余协议):
- 多台机器组成一个"VRRP 路由器组",共享一个 VIP
- 选出一台 Master,其他是 Backup
- Master 周期性(默认 1 秒)发送 VRRP 通告(advertisement)
- Backup 收不到通告(连续 3 次 = 3 秒)就认为 Master 挂了,自己升级为 Master,接管 VIP
- Master 恢复后默认会"抢占"回 VIP(可通过
nopreempt关闭)
💡 原理:为什么是 3 秒而不是立刻切换?
默认 3 秒切换是权衡:
- 太快(< 1 秒):网络抖动会被误判为故障,导致"双 Master"脑裂
- 太慢(> 10 秒):业务已经超时,用户感知到中断
3 秒是保守且工程化的折中值。生产环境可通过
vrrp_script自定义健康检查,把切换时间压到 1-2 秒。
3.3 Keepalived 配置实战(主备模式)
3.3.1 准备 2 台机器
| 角色 | IP | 说明 |
|---|---|---|
| Master | 192.168.1.10 | 主 Nginx,持有 VIP |
| Backup | 192.168.1.11 | 备 Nginx,平时空闲 |
| VIP | 192.168.1.100 | 对外服务的虚拟 IP |
两台机器都装好 Nginx(监听 VIP)+ Keepalived。
3.3.2 Master 配置 /etc/keepalived/keepalived.conf
| |
3.3.3 Backup 配置(只改 3 处)
| |
3.3.4 健康检查脚本 /usr/local/bin/check_nginx.sh
| |
| |
3.3.5 启动与验证
| |
3.4 Nginx 端的 5 个真实 keepalive 参数
Nginx 跟后端保持长连接这 5 个参数必须配对出现,少一个就掉坑里:
| |
| 参数 | 作用 | 不配的后果 |
|---|---|---|
keepalive 32 | 启用连接池 | 每次新建 TCP 连接,性能差 5 倍 |
proxy_http_version 1.1 | HTTP/1.1 协议 | 1.0 不支持 keepalive |
proxy_set_header Connection "" | 清空 Connection 头 | 后端收到 Connection: close 主动关连接 |
keepalive_timeout 60s | 连接池超时 | 连接长时间不释放 |
keepalive_requests 1000 | 单连接最多请求数 | 防止单个长连接无限累积状态 |
🎯 避坑点:
Connection: close是隐形杀手
proxy_set_header Connection ""这一行看起来"无关紧要",实际上是最容易踩的坑。如果不写,Nginx 默认会把客户端的Connection: close透传给后端,后端收到后主动关闭 TCP 连接——keepalive 形同虚设。现象:监控看到 Nginx 到后端的连接数正常,但后端
netstat -an看到大量 TIME_WAIT 状态。100% 是这个参数没配。
3.5 脑裂:Keepalived 最大的坑
脑裂(split-brain):Master 和 Backup 同时认为自己是 Master,同时持有 VIP。结果:
- 用户请求被随机分到两台机器
- 两台机器状态不一致,数据被双向覆盖
- 监控告警狂响,运维一脸懵
脑裂的 3 大成因:
- 网络分区:Master 和 Backup 之间的心跳线中断,但 Master 实际还活着
- 防火墙拦截 VRRP 通告:VRRP 用多播地址
224.0.0.18,某些安全策略会拦 - 优先级配置错误:两台机器优先级都设成 100,谁都觉得自己是 Master
脑裂的 3 道防线:
| |
🛑 误区警示:脑裂 = 数据灾难
脑裂一旦发生,比单点故障更可怕。单点故障至少业务中断是确定的,脑裂是"两台机器各自服务一部分用户,状态还不一致"——数据被双向覆盖,等发现时已经无法回滚。
防御永远比治疗重要:单播 VRRP + 独立心跳线 + 业务侧冲突检测,三道防线缺一不可。
四、LVS:跨城市流量调度的内核王牌
4.1 为什么需要 LVS:Nginx 的天花板
Nginx + Keepalived 能扛 1-5 万 QPS(同城双活),但遇到大促、双 11 之类 50 万 QPS 场景就远远不够。Nginx 是用户态进程,受限于:
- 单进程事件循环(虽然多 worker 提升有限)
- HTTP 协议解析开销
- 内存带宽
LVS 走的是另一条路:直接在内核协议栈里转发数据包,根本不进入用户态。理论上限是几十万到百万 QPS,是 Nginx 的 10-50 倍。
4.2 LVS 的 4 种工作模式
LVS 有 4 种转发模式(NAT / DR / TUN / FULLNAT),每种对应不同的网络拓扑:
4.2.1 NAT 模式(Network Address Translation)
特点:
- 进出都经过 LVS(进出流量都改 IP)
- Real Server 可以跨网段(甚至跨 VLAN)
- LVS 是性能瓶颈(双向流量都过它)
- 适合小规模、Real Server 少的场景
4.2.2 DR 模式(Direct Routing,直接路由)⭐ 最常用
特点:
- 请求进 LVS,响应直接出 Real Server(响应不经过 LVS)
- LVS 只负责"改 MAC 地址"(L2 转发)
- 性能最高(LVS 只承担一半流量)
- Real Server 必须和 LVS 在同一 VLAN(L2 互通)
- Real Server 需要配置 VIP 在 lo 网卡上(让它能处理目的 IP 是 VIP 的包)
💡 原理:DR 模式为什么快?
DR 模式 LVS 做的只是改 MAC 地址——把数据包的目的 MAC 从 LVS 自己的改成 Real Server 的。包头 IP 都不动。
整个过程在内核的
IPVS模块完成,单次转发 < 10 微秒。而 NAT 模式要改 IP + 改端口 + 算校验和,慢 10 倍。
4.2.3 TUN 模式(IP Tunneling,IP 隧道)
把数据包再封装一层 IP 头,通过隧道发给 Real Server。Real Server 可以跨地域(公网可达即可),但需要在 Real Server 上做解封装。
4.2.4 FULLNAT 模式(阿里独创)
双向都做 SNAT + DNAT,Real Server 看不到客户端真实 IP(双向都改 IP)。解决了 DR 模式必须同 VLAN 的限制,是阿里云 SLB 的核心实现。
4.2.5 4 种模式对比
| 模式 | 性能 | Real Server 跨网段 | Real Server 看到真实 IP | 配置复杂度 | 典型场景 |
|---|---|---|---|---|---|
| NAT | 中(双向过 LVS) | ✅ | ✅ | 低 | 小规模、内网环境 |
| DR | ⭐⭐⭐ 最高 | ❌(必须同 VLAN) | ✅ | 中 | 同城机房(最常用) |
| TUN | 中 | ✅(隧道可达) | ✅ | 高 | 跨地域、异构网络 |
| FULLNAT | 中高 | ✅ | ❌ | 高 | 云厂商、跨 VPC |
4.3 IPVS:LVS 的内核态实现
LVS 本身是一个框架,核心实现叫 IPVS(IP Virtual Server),是 Linux 内核 2.6 后内置的模块:
| |
IPVS vs iptables:很多人误以为 LVS 是用户态工具,其实所有转发逻辑都在内核。ipvsadm 只是配置命令(ipvsadm -A -t VIP:80 -s rr 添加规则),规则写入内核后,包转发完全在内核态完成。
4.4 LVS 调度算法
LVS 支持 10+ 种调度算法,常用的有 5 种:
| 算法 | 含义 | 适用场景 |
|---|---|---|
| rr(Round Robin) | 轮询 | 后端性能一致(最常用) |
| wrr(Weighted RR) | 加权轮询 | 后端性能不均 |
| lc(Least Connection) | 最少连接 | 长连接服务 |
| wlc(Weighted LC) | 加权最少连接 | ⭐ 推荐默认 |
| sh(Source Hashing) | 源 IP 哈希 | 需要会话保持 |
| |
-g 表示 DR 模式(gatewaying),-m 是 NAT,-i 是 TUN。
4.5 LVS 真实性能数据
生产环境的 LVS 集群典型数据:
| 业务 | LVS 模式 | Real Server 数 | 峰值 QPS | 备注 |
|---|---|---|---|---|
| 阿里云 SLB | FULLNAT | 数百 | 千万级 | 单集群扛住双 11 |
| 美团 MGW | DR | 数十 | 百万级 | 入口流量调度 |
| 某电商大促 | DR | 8 | 50 万 | 单机房 |
| 某金融核心 | NAT | 4 | 5 万 | 强一致场景 |
📌 实践:LVS 的"理论极限"
单 LVS 节点性能上限取决于包转发能力(pps):
- 普通服务器(千兆网卡):148 万 pps ≈ 50 万 QPS(小包)
- DPDK 优化:千万 pps
- 内核优化(
irqbalance、RPS/RFS):300 万 pps实际生产中 LVS 不会是瓶颈——网络才是。千兆网卡满载 = 148 万 pps ≈ 50 万 HTTP QPS(按平均 200 字节包算)。
4.6 LVS 的历史与章文嵩的故事
讲 LVS 不能不提它的作者——章文嵩。1998 年他还是国防科技大学的一名博士生,因为实验室的 Web 服务器扛不住大量并发访问,自己动手写了 IPVS 模块并贡献给 Linux 内核。这是中国人主导的、为数不多的内核级基础设施项目。
LVS 的几个关键时间节点:
- 1998:章文嵩在国防科大开发 LVS 1.0 版本
- 2002:LVS 2.0 发布,加入 NAT / DR / TUN 三种模式
- 2004:IPVS 正式并入 Linux 2.6 内核主线
- 2010s:阿里基于 LVS 开发 FULLNAT 模式,解决云环境跨 VPC 问题
- 2020s:LVS 仍是云厂商负载均衡的事实标准内核
💡 原理:为什么 LVS 20 年不过时?
LVS 之所以能在 Service Mesh、Envoy、eBPF 等新技术层出不穷的今天仍占据入口调度,核心原因:它在内核。任何用户态的方案(Nginx / HAProxy / Envoy)都要走系统调用 → 内核协议栈的路径,而 LVS 本身就在内核协议栈里,少一次上下文切换就少 5-10 微秒。
这是物理规律决定的,不是软件能优化的。eBPF 虽然也在内核,但目前 L4 场景仍未全面取代 IPVS。
4.7 LVS vs HAProxy:4 层反代的"双雄之争"
HAProxy 也是 4 层反代的常见选择(同公司还有 Nginx Ingress 也在用),与 LVS 形成竞争:
| 维度 | LVS | HAProxy |
|---|---|---|
| 实现位置 | Linux 内核(IPVS) | 用户态进程 |
| 性能 | 百万级 QPS | 10-30 万 QPS |
| 配置复杂度 | 中(ipvsadm 命令) | 低(haproxy.cfg 文件) |
| 健康检查 | TCP_CHECK / HTTP_GET | 更丰富(支持脚本) |
| 日志 | 内核态,无业务日志 | 详细业务日志 |
| 典型场景 | 入口抗量、超大规模 | 中等规模、需业务可观测 |
实战选择:
- 超大规模(> 50 万 QPS):LVS
- 中等规模 + 需详细日志:HAProxy
- 云环境 / 容器环境:HAProxy(K8s 默认 kube-proxy 用的就是 iptables/IPVS,HAProxy 在 Ingress 层常见)
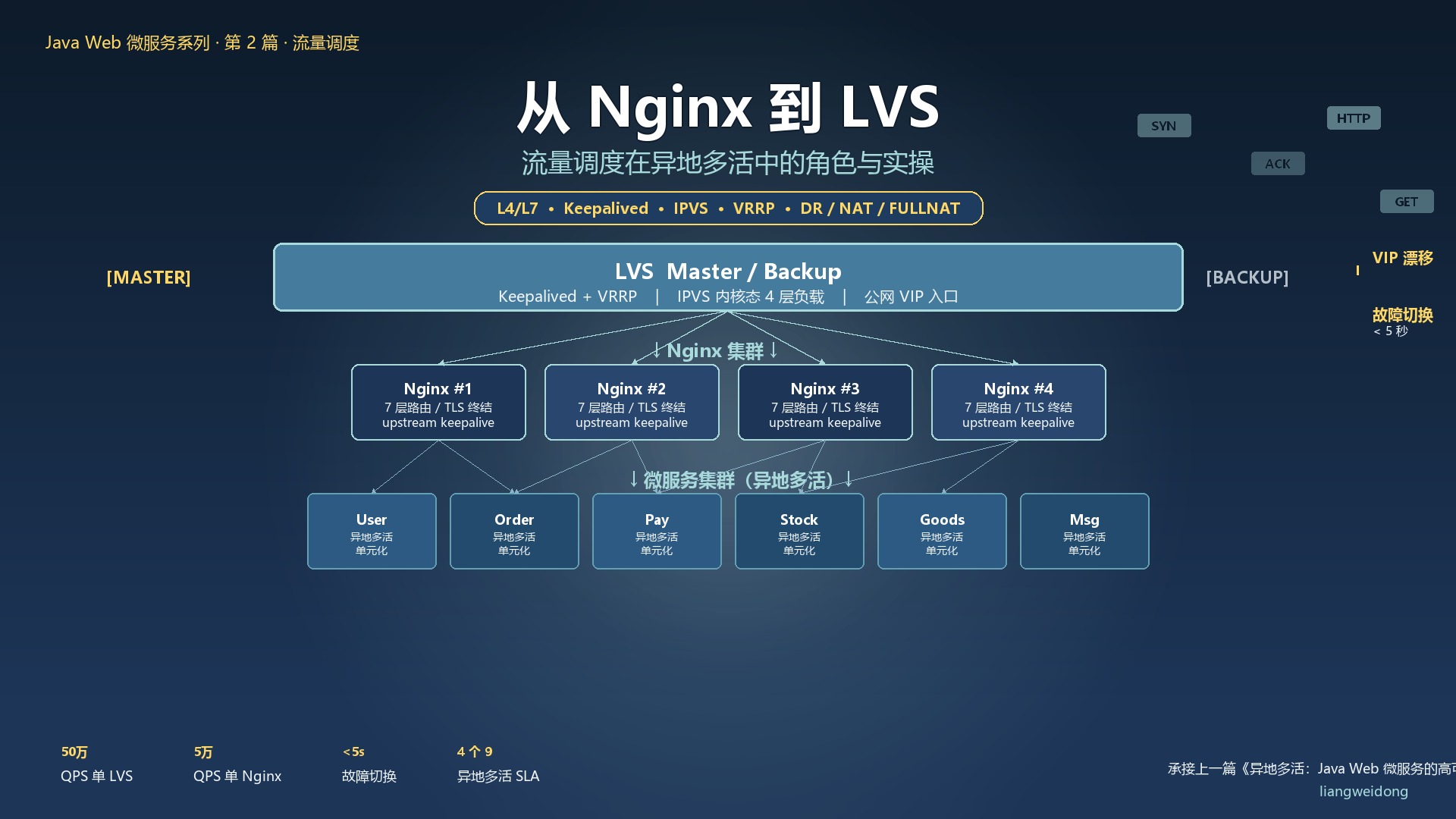
五、LVS + Keepalived + Nginx:异地多活流量层完整链路
5.1 经典三层塔架构
把 LVS、Keepalived、Nginx 串起来,就是异地多活流量层的"前哨班"完整链路:
为什么需要 3 层而不是直接 LVS → App?
- LVS 看不到 HTTP 头:无法按 Host / URL 路由(4 层限制)
- LVS 无法终结 TLS:HTTPS 终结在 Nginx 更省 CPU
- LVS 无法做应用层健康检查:Nginx 的
upstream_check模块能做更精细的健康探测
💡 原理:三层塔的职责边界
- LVS 层:抗量 + 故障切换(不在乎协议内容)
- Nginx 层:七层路由 + TLS 终结 + 应用层健康检查
- 应用层:业务逻辑 + 微服务路由
每一层只做自己擅长的事,这是分布式系统设计的"第一性原则"。
5.2 双 Keepalived 实例设计
实战中,LVS 层和 Nginx 层都要 Keepalived 保护:
2 个 Keepalived 实例的分工:
- Keepalived 1(外层):保 LVS,VIP 是公网入口
- Keepalived 2(内层):保 Nginx,VIP 是内网入口
双 VIP 的好处:
- LVS 切换不影响 Nginx:LVS 挂了,Nginx 还在,对应用零感知
- Nginx 切换不影响 LVS:Nginx 挂了,LVS 还在,VIP 还在
- 故障定位更细:告警能精确到"LVS 层故障"或"Nginx 层故障"
5.3 阿里 / 美团 / 字节的真实架构
5.3.1 阿里云 SLB
阿里云 SLB(Server Load Balancer)的内核就是 LVS + Tengine 的组合:
- LVS 集群(FULLNAT 模式):公网入口,扛 100 万级 QPS
- Tengine 集群:七层路由 + 业务分流
- 多 AZ 部署:同城双活 + 异地灾备
关键技术:
- FULLNAT 模式(阿里自研):Real Server 跨 VPC 部署
- ECS 健康检查:30 秒无响应自动剔除
- 会话保持:基于 Cookie 4 层哈希
5.3.2 美团 MGW
美团自研的 MGW(Meituan Gateway)架构:
- HAProxy 做 L4:替代 LVS,部分场景性能更好
- Tengine 做 L7:替代纯 Nginx,加了很多自研模块
- 多机房单元化:MGW 内部带"机房标签"
5.3.3 字节跳动 BFE
字节的 BFE(Baidu Front End,注:字节和百度都叫 BFE):
- 七层网关为主:直接用 Go 自研 BFE 做入口
- Service Mesh 协同:跨机房调用通过 Mesh 自动处理
- 多语言 SDK:Go / Java / Python 都接入
📌 实践:自研还是用开源?
- < 50 万 QPS:直接用 LVS + Keepalived + Nginx,业界成熟方案
- 50 万 - 500 万 QPS:LVS + Tengine + 自研健康检查平台
- > 500 万 QPS:必须自研(参考阿里 SLB、美团 MGW、字节 BFE)
不要过早自研。开源方案 80% 场景够用,自研成本是 5-10 倍。
5.4 异地多活的流量调度策略
5.4.1 DNS 层:用户就近接入
- 智能 DNS:根据用户 IP 归属地返回最近的 VIP
- 健康检查融合:DNS 探测机房健康度,故障机房自动从 DNS 摘除
- DNS TTL 权衡:TTL 太短切换快但 DNS 压力大,太长切换慢
5.4.2 应用层:单元化路由
承接系列第 1 篇的单元化设计——LVS 不做单元化判断,单元化路由在 Nginx 或 Spring Cloud Gateway 层做:
| |
5.4.3 故障切换:DNS + LVS 双层
机房级故障时:
- DNS 切流(分钟级):把 VIP 摘除,流量自动去其他机房
- LVS VIP 切流(秒级):同机房内 Keepalived 切换
- Nginx upstream 切流(毫秒级):健康检查失败自动剔除
3 层切换配合:DNS 解决"机房级"、LVS 解决"机器级"、Nginx 解决"应用级"。
5.5 为什么 K8s 内部不直接用 Service/Ingress 而要 LVS?
很多读者会问:"我已经在 K8s 上了,为什么入口还要 LVS?"
K8s 内部确实有 Service(kube-proxy 实现)和 Ingress(nginx-ingress / traefik),但它们只解决"集群内"问题,解决不了"集群外"问题:
| 层级 | K8s 组件 | 解决的问题 | 解决不了的问题 |
|---|---|---|---|
| Pod → Pod | kube-proxy (iptables/IPVS) | 集群内服务发现 + 负载均衡 | 公网入口 |
| 集群入口 | Ingress (nginx-ingress) | 七层路由 + TLS 终结 | 抗量级(单 ingress 几万 QPS) |
| 机房入口 | LVS / 硬件 LB | 抗量 + 故障切换 | 业务路由 |
| 跨机房 | DNS 调度 | 用户就近接入 | 秒级切流 |
K8s 环境的典型架构:
LVS 在 K8s 环境承担的角色:
- 抗量:nginx-ingress 单实例最多 1-3 万 QPS,几十个 pod 才能扛百万级
- 入口高可用:nginx-ingress pod 漂移,VIP 还在 LVS 上
- 跨节点均衡:多个 ingress pod 分布在不同节点,LVS 统一对外
📌 实践:K8s 入口的 3 种方案
- LVS + nginx-ingress(推荐):抗量 + 高可用 + 业务路由齐全
- 云厂商 LB + nginx-ingress:省运维,付出云费用
- 纯 Ingress(不要 LVS):只适合中小规模,大促会爆
六、4 种方案选型矩阵 + 真实案例
6.1 选型矩阵
| 方案 | 抗量级 | RTO | 复杂度 | 成本 | 适用场景 |
|---|---|---|---|---|---|
| 单机 Nginx | 1-3 万 QPS | 不可用 | 最低 | 1x | Demo、内部工具、低可用业务 |
| Nginx + Keepalived 双机 | 1-5 万 QPS | < 10 秒 | 低 | 2x | 中小业务、3 个 9 可用性 |
| LVS-DR + Nginx + Keepalived | 5-50 万 QPS | < 5 秒 | 中 | 3-4x | 同城双活主流方案 |
| LVS + Keepalived + Nginx 三层塔 | 10-100 万 QPS | < 3 秒 | 高 | 5-8x | 异地多活、大促、4 个 9 |
| 自研 LB(SLB / MGW / BFE) | > 100 万 QPS | < 1 秒 | 极高 | 10x+ | 阿里、美团、字节级别 |
6.2 真实案例对照
| 公司 | 流量调度方案 | 特点 |
|---|---|---|
| 某 SaaS 初创(日活 5 万) | 单机 Nginx | 1 台 4C8G 跑一年,挂了重启 5 分钟 |
| 某电商中型(日活 100 万) | Nginx + Keepalived 双机 | 2 台 8C16G,3 个 9 可用性 |
| 美团外卖 | MGW(自研 HAProxy + Tengine) | 单元化 + 异地双活 |
| 阿里双 11 | SLB(LVS + Tengine) | 三地五中心,50 万 + QPS |
| 字节 TikTok | BFE(自研 Go 网关) | 海外多 Region |
6.3 决策流程
6.4 反例:选错的代价
反面案例 1:金融初创选了"单机 Nginx"
某支付初创公司 2019 年上线,日活 5 万,CTO 觉得"用 LVS 成本太高",选了单机 Nginx。2020 年春节红包活动,单机 Nginx 进程被大流量打挂,业务中断 2 小时。事后估算损失 200 万,远超"上 LVS 节省的 30 万成本"。
教训:成本不是按"现在用不用得上"算,是按"挂了损失多少"算。即使是中小业务,强一致性场景也要至少 Nginx + Keepalived。
反面案例 2:电商中型选了"LVS 但没配 Keepalived"
某电商 2021 年自建机房,CTO 觉得"单 LVS 够用"。结果 LVS 机器硬件故障(电源烧了),入口整个挂掉,所有用户访问超时。事后抢修换机器,1 小时恢复。
教训:LVS 本身是高可用组件里的"被保"对象。没有 Keepalived 保护,LVS 挂了入口就挂。永远要有"保 LVS 的人"。
反面案例 3:直播平台选了"LVS + Nginx 但没做异地多活"
某直播平台 2022 年大促,所有流量集中在北京机房。北京机房的光纤被市政施工挖断,平台全挂 6 小时。事后损失数千万。
教训:LVS + Nginx 解决的是"机房内"容灾,“机房外"必须异地多活。两个层次都要做,不能只看一个。
6.5 选型决策清单
| 业务特征 | 推荐方案 |
|---|---|
| 日活 < 10 万、可用性要求低 | 单机 Nginx |
| 日活 10-100 万、3 个 9 | Nginx + Keepalived |
| 日活 10-100 万、强 SLA 4 个 9 | LVS + Keepalived + Nginx 三层塔 |
| 日活 > 100 万、4 个 9 | LVS 三层塔 + 异地多活 |
| 日活 > 1000 万 或 上市级 SLA | 自研 LB(参考 SLB / MGW / BFE) |
🎯 避坑点:选型不是越贵越好
见过最离谱的案例:日活 2 万的内部 OA 系统,上了 LVS + Keepalived + 自研监控全套。3 个人的运维团队维护 6 台服务器,效率极低。
选型原则:用最少的组件满足需求。日活 2 万单机 Nginx 就够,别为了"高可用"过度设计。
七、实操手册:一步步搭建 LVS + Keepalived + Nginx
本节是完整可复制粘贴的命令清单。准备 3 台 Linux 机器(CentOS 7 或 Ubuntu 20.04+),按角色分配:
| 角色 | IP | 用途 |
|---|---|---|
| LVS-Master | 192.168.1.10 | LVS 主节点(也做 Keepalived Master) |
| LVS-Backup | 192.168.1.11 | LVS 备节点(也做 Keepalived Backup) |
| Nginx-Real | 192.168.1.20 | 后端 Nginx 真实服务器(DR 模式) |
| VIP | 192.168.1.100 | 对外服务的虚拟 IP |
💡 小贴士:至少 2 台机器也能跑(Real Server 用 Docker 启 Nginx 模拟)。生产环境请按上面 3 台分配。
7.1 准备环境
7.1.1 关闭防火墙和 SELinux
| |
7.1.2 开启 IP 转发(DR 模式必需)
| |
7.2 安装 IPVS(LVS 内核模块)
| |
7.3 安装 Nginx(Real Server 上)
| |
🎯 避坑点:arp_ignore / arp_announce 必须配
这是 DR 模式最容易踩的坑。不配的话:
- arp_ignore = 0(默认):Real Server 会对 ARP 请求"积极响应”,把 VIP 的 MAC 地址告诉别人
- 结果:外部请求都到 Real Server 了,LVS 收不到包
arp_ignore = 1:只对"目标 IP 是本机接口的"ARP 请求响应。配合 arp_announce = 2(只向同网段宣告自己接口的 IP)才能正常工作。
启动 Nginx:
| |
7.4 安装 Keepalived
| |
7.4.1 LVS Master 配置 /etc/keepalived/keepalived.conf
| |
7.4.2 LVS Backup 配置(只改 3 处)
| |
7.4.3 健康检查脚本
| |
| |
7.4.4 启动 Keepalived
| |
7.5 验证整套链路
| |
7.6 故障演练
| |
📌 实践:nopreempt 是好习惯
默认 Keepalived 会在 Master 恢复后自动抢占回 VIP。这种行为在生产中容易导致"脑裂"(短暂的"双 Master")。
配 nopreempt 后:Master 恢复后保持 Backup 状态,只有 Backup 挂了才接管。切换更稳定,但要手动维护(定期巡检 VIP 是否在期望的机器上)。
7.7 配套 Nginx upstream
如果 Real Server 跑的不是裸 Nginx,而是反向代理(Nginx → 多个微服务),配置就稍微复杂:
| |
3 个 ⭐ 参数:
keepalive 32:与后端保持 32 个长连接池proxy_http_version 1.1:HTTP/1.1(keepalive 必须)proxy_set_header Connection "":清空 Connection 头(避免后端主动关闭)
7.8 容器化场景:Docker / K8s 下的等价配置
如果你的后端服务跑在 Docker / K8s 容器里,Nginx 的 upstream 配置需要相应调整:
Docker Compose 场景:
| |
对应的 Nginx upstream(用容器名代替 IP):
| |
K8s 场景:
| |
📌 实践:K8s 中 keepalive 的"坑"
K8s 中 Pod IP 随时可能变化(重启、调度、扩缩容)。如果把 Pod IP 写死在 upstream 里,Pod 重启一次就全部失效。
正确做法:用 Service 的 DNS 名称(
myapp.default.svc.cluster.local),Nginx 启动时 DNS 解析一次。Service 后端 Pod 变化时,长连接池内残留的旧连接会失败,触发自动重连。
7.9 性能压测:wrk 与 ab 实战
搭建完链路后,必须做压测确认性能。推荐 2 个工具:
wrk(推荐,Lua 脚本扩展):
| |
ab(Apache Bench,简单场景):
| |
压测要看 P99 延迟,不要只看平均:
- 平均延迟 5ms,但 P99 500ms → 长尾问题严重
- P99 < 50ms 才算健康
八、踩坑与监控
8.1 10 个常见坑速查
| # | 坑 | 现象 | 解决 |
|---|---|---|---|
| 1 | arp_ignore / arp_announce 没配 | LVS 收不到包,外部直接连 Real Server | Real Server 上配 arp_ignore=1, arp_announce=2 |
| 2 | Nginx upstream 没配 keepalive | TIME_WAIT 飙升,端口耗尽 | 加 keepalive 32 + proxy_http_version 1.1 + Connection "" |
| 3 | Keepalived 脑裂 | 双 Master 互相抢 VIP | 单播 VRRP + 独立心跳线 + 业务侧冲突检测 |
| 4 | LVS DR 模式跨 VLAN | Real Server 收不到 ARP | 同 VLAN 部署,或换 FULLNAT |
| 5 | VIP 漂移后 ARP 表未更新 | 客户端缓存旧 MAC 地址 | 在 LVS 配 notify_master 脚本,主动广播 gratuitous ARP |
| 6 | nopreempt 没配 | Master 恢复后双 Master 抢 VIP | 配 nopreempt,避免频繁切换 |
| 7 | LVS Master 单点 | LVS 挂了整个入口挂 | 必须 Keepalived 双机 + 监控 |
| 8 | ip_forward 没开 | DR 模式包转发失败 | sysctl -w net.ipv4.ip_forward=1 |
| 9 | Real Server lo:0 没绑 VIP | 拒绝服务(认为非本机 IP) | Real Server 上 ifconfig lo:0 VIP netmask 255.255.255.255 |
| 10 | LVS 健康检查误判 | 偶发抖动导致全摘 | 调大 nb_get_retry 和 delay_before_retry |
8.2 监控告警
8.2.1 必监控指标
| 指标 | 阈值 | 工具 |
|---|---|---|
| VIP 是否在期望机器上 | 漂移即告警 | Keepalived notify_* 钩子 + Prometheus |
| IPVS 活跃连接数 | > 80% 容量告警 | ipvsadm -Ln + node_exporter |
| Real Server 健康状态 | 任何 down 立即告警 | Keepalived virtual_server 块内置检查 |
| LVS Master / Backup 进程存活 | 进程消失告警 | systemd + Prometheus |
| Nginx upstream 失败率 | > 1% 告警 | Nginx ngx_http_upstream_check_module |
| 跨机房专线延迟 | > 50ms 告警 | 自研 ping 探针 |
8.2.2 拨测(公网心跳)
| |
拨测要部署在公网,机房内的监控不能替代公网探测。
🎯 避坑点:监控盲区
最常见的监控盲区是"机房内一切正常,机房外访问不到"。常见原因:
- 机房出口防火墙拦截
- 跨机房专线中断
- 公网 BGP 路由异常
唯一可靠的判断是"公网能否正常访问"。拨测是异地多活的"生命线"。
8.3 3 个真实故障案例(公开复盘整理)
案例中数字来源于公开复盘报告,已脱敏处理。重点看"现象 → 根因 → 修复"三段式分析。
案例 1:Keepalived 切换抖动导致业务频繁超时
- 现象:某电商 2022 年大促,业务监控发现每隔 30-60 秒就有 1-2 秒的请求超时。QPS 越高峰越明显。
- 根因:Keepalived 主备之间的 VRRP 心跳被交换机 MAC 表老化干扰,导致短暂的双 Master / 双 Backup 切换。每次切换有 1-2 秒的 ARP 重学习窗口,期间流量黑洞。
- 修复:(1) 调整交换机 MAC 表老化时间到 30 分钟;(2) Keepalived 配
unicast_src_ip单播模式,避免多播丢包;(3) 监控加上"VIP 1 分钟内切换次数"告警。
案例 2:LVS DR 模式跨 VLAN 部署,ARP 全部失败
- 现象:某金融公司 2021 年新机房部署 LVS,所有请求都直连到 Real Server,LVS 收不到包。Keepalived 健康检查一直告警。
- 根因:运维把 LVS 和 Real Server 放在不同 VLAN(中间隔了路由器),但 LVS DR 模式是 L2 转发,L2 广播域不通就无法做 ARP 替换。
- 修复:(1) 把 LVS 和 Real Server 改到同一 VLAN;(2) 如果必须跨 VLAN,改用 FULLNAT 模式(阿里云方案);(3) 在网络拓扑图里显式标注 LVS 边界,避免后续运维踩坑。
案例 3:nginx keepalive 配置错,TPS 暴跌 70%
- 现象:某 SaaS 公司 2023 年迁移到新机房,TPS 从 5000 降到 1500,后端 CPU 反而飙到 90%。
- 根因:运维在 nginx.conf 里漏了
proxy_set_header Connection ""(Nginx 模板是复制的,这一行没复制到)。结果后端收到Connection: close主动关闭 TCP 连接,每秒多 5000 次 3 次握手 + 4 次挥手。 - 修复:(1) 补全 3 个 keepalive 参数;(2) 加上
wrk压测 baseline 监控,配置变更后自动对比基线;(3) 把 3 个 keepalive 参数写进 Ansible 模板,代码化防止遗漏。
🛑 误区警示:3 个案例的共性
这 3 个案例的共性:
- 配置层面的错误,不是软件 bug
- 监控告警虽然响了,但没被及时处理(大促期间没空看)
- 变更没有"基线对比"——配置改完没和历史数据对比,TPS 跌 70% 都没发现
防御方法:
- 配置变更走 PR + 评审 + 灰度
- 关键指标(TPS / P99 / 错误率)配基线告警(偏离基线 30% 立刻报警)
- 重要配置写进代码(Ansible / Helm Chart),不要让人肉 cp 配置文件
8.4 5 条运维铁律
最后给做流量调度的运维 5 条铁律:
- 任何变更先在预发环境跑 1 周:配置错误往往不是立即暴露,是运行 3-7 天后才出问题(如内存泄漏、连接耗尽)
- 关键配置做成"代码":用 Ansible / Helm Chart 管理,避免人肉 cp 配置文件
- 监控 + 告警 + Runbook 三件套:监控发现问题,告警通知人,Runbook 指导人怎么修。缺一不可
- 故障演练常态化:每月 1 次小演练,季度 1 次大演练。没演练过的高可用 = 假高可用
- 复盘文化:每次故障 24 小时内复盘,输出 Action Item 并跟踪。不复盘的故障 = 还会再发生
总结
9.1 流量调度的演进小结
演进的内在动力:
- 业务量增长 → 单机撑不住 → 多机
- 可用性要求提高 → 单点故障不能接受 → Keepalived
- 性能天花板 → Nginx 不够 → LVS
- 极致性能 + 异地多活 → 三层塔 + 自研
9.2 3 大核心要素
承接系列第 1 篇的"业务 / 数据 / 流量"三分法,流量调度层的 3 大核心:
- 冗余:每层都有主备,任意一层挂了下一层接住
- 分层:LVS 抗量 / Nginx 路由 / App 业务,各司其职
- 自动化:健康检查 + 自动剔除 + 自动接管,无需人工介入
9.3 系列预告
这是 Java Web 微服务系列 的第 2 篇。后续计划:
- 第 3 篇:Spring Cloud Gateway:应用层网关的精细化治理 —— 微服务内部路由、灰度、限流、鉴权
- 第 4 篇:Nacos + Sentinel + Seata 三件套实战 —— 服务发现 + 流量治理 + 分布式事务
- 第 5 篇:SkyWalking 全链路追踪 —— 异地多活下的链路可观测性
- 第 6 篇:自研 LB 设计要点 —— 100 万 QPS 级别的流量调度系统
回到系列开篇的命题:异地多活不是"装个软件就完事",是"用钱换命“的系统工程。流量调度作为"前哨班”,看似只是几个开源组件的拼接,实际踩过的坑足够写 100 篇博客。
本篇的实操清单是"最小可运行版本",生产环境请结合 §8.2 的监控指标 + 业务场景做调整。异地多活的"前哨班"搭好了,业务系统的可用性才能真正"扛得住"。
附录:常见问题 FAQ
本节是面向架构评审、面试、新人入职的速查清单——把读者最常问的问题集中解答。
A1:LVS 和 Nginx 能不能装在同一台机器上?
技术上可以,生产上不推荐。
LVS 是内核态转发,Nginx 是用户态进程。装同一台会:
- 资源争抢:LVS 转发吃 CPU,Nginx 处理 HTTP 也吃 CPU,互相挤兑
- 故障域重叠:机器挂了 LVS 和 Nginx 一起挂,双层塔降级成单层
- 监控混乱:出问题时分不清是 LVS 还是 Nginx 的锅
正确做法:LVS 机器只跑 LVS + Keepalived,Nginx 机器只跑 Nginx + 应用。职责单一。
A2:Keepalived 主备之间是用多播还是单播?
生产环境推荐单播(unicast_src_ip + unicast_peer)。
多播(默认)的问题:
- 很多云厂商默认禁止多播(224.0.0.0/4 段)
- 跨网段多播经常被丢
- 安全扫描工具会报"未加密的多播协议"漏洞
单播的优点:
- 点对点通信,经过路由器也能通
- 更安全(不会被同网段其他机器听到 VRRP 通告)
- 可观测(TCP 单播能用 tcpdump 抓包分析)
A3:DR 模式下 Real Server 为什么需要把 VIP 绑到 lo 网卡?
因为 DR 模式 LVS 只改目的 MAC、不改目的 IP。Real Server 收到包后发现目的 IP 是 VIP,不是自己的 IP(如 192.168.1.20),默认会丢弃(认为不是发给自己的)。
把 VIP 绑到 lo 网卡后,Real Server 觉得"这个 IP 是我的",会正常处理。lo 是 loopback 接口,不对外,所以不会引起 ARP 冲突。
A4:Keepalived 检测到 Nginx 挂了,VIP 切到 Backup,但 Backup 的 Nginx 没起来怎么办?
典型场景:Keepalived 进程比 Nginx 进程先起。
Keepalived 默认只检测自身进程是否存活,不会检查 Nginx。所以 Nginx 没起来,Keepalived 也会把 VIP 拉过来——用户访问 VIP,结果是连接被拒。
正确做法:用 vrrp_script 自定义健康检查(参考 §3.3.2 脚本):
| |
脚本返回非 0 = 优先级降 20 = 自动让出 VIP。这样只有 Nginx 也起来了,Backup 才接管 VIP。
A5:异地多活的流量调度和同城双活的本质区别是什么?
同城双活:机房之间 RTT < 5ms,LVS/Nginx 跨机房 RPC 几乎无感。技术上同城双活就是"在一个城市里"。
异地多活:机房之间 RTT 30-100ms,任何跨机房调用都是 60-200 倍延迟。所以严格禁止跨机房 RPC,必须靠单元化路由 + DNS 调度让用户"绑死"在一个机房。
对应到流量调度:
- 同城双活:LVS 可在机房之间漂移(Keepalived + 跨机房心跳)
- 异地多活:每个机房一套独立的 LVS + Keepalived 集群,机房之间通过 DNS 互导
A6:硬件 LB(F5 / A10)和软件 LVS 怎么选?
| 维度 | 硬件 LB | 软件 LVS |
|---|---|---|
| 性能 | 千万级 QPS | 百万级 QPS |
| 成本 | 几十万到上百万 | 几千到几万 |
| 可定制 | 黑盒,只能配 | 完全开源,可深度定制 |
| 故障恢复 | 厂商技术支持 | 靠自己 |
| 典型用户 | 银行、证券、政企 | 互联网公司 |
实战选择:
- 钱多 + 求稳:硬件 LB
- 钱紧 + 求灵活:LVS(互联网公司主流)
- 混合:核心入口用硬件 LB,业务入口用 LVS
A7:为什么很多公司直接用云厂商 LB 而不自己搭 LVS?
直接原因:省事。云厂商 LB 帮你搞定:
- 多 AZ 高可用(自带 Keepalived)
- 健康检查 + 自动剔除(自带 LVS 健康检查)
- 跨 Region 调度(自带 DNS 调度)
- DDoS 防护(云厂商自带)
- TLS 终结(证书托管)
深层原因:大部分公司没有"自建 LB"的运维能力。一个 5 人运维团队,维护业务都吃力,没人专门优化 LVS 内核参数。用云厂商 LB 是 ROI 更高的选择。
自建 LVS 的场景:
- 业务量足够大(单 LB 月费用 > 50 万)
- 有专门的 SRE 团队
- 公有云满足不了的特殊需求(如跨云、混合云)
A8:流量调度层和应用层网关(Spring Cloud Gateway)是什么关系?
层级不同:
| 层级 | 职责 | 典型组件 |
|---|---|---|
| 流量调度层(本篇) | 机房入口 + 抗量 + 7 层路由 | LVS、Nginx、HAProxy |
| 应用层网关(系列第 3 篇) | 微服务内部路由 + 灰度 + 限流 + 鉴权 | Spring Cloud Gateway、Kong、APISIX |
举例:
- 用户访问
https://api.example.com/order→ LVS → Nginx(按 host 路由)→ Spring Cloud Gateway(按 URL 路由到 order 微服务)→ order 服务 - Nginx 只看 host / URL 前缀,Spring Cloud Gateway 看完整微服务元数据(服务名、版本、灰度标签)
性能差异:
- LVS 单实例 50 万 QPS
- Nginx 单实例 1-5 万 QPS
- Spring Cloud Gateway 单实例 1-5 千 QPS(Java 业务逻辑开销)
所以入口用 LVS/Nginx 抗量,业务内部用 Spring Cloud Gateway 精细治理,两个层都不可少。
A9:怎样评估"流量调度层是否需要升级"?
3 个信号:
- 容量告警:
ipvsadm -Ln看到活跃连接数持续 > 80% 单机容量 - 延迟告警:监控显示 P99 延迟持续上涨,已经超过业务容忍上限
- 故障切换告警:Keepalived 1 周内切换 > 3 次,说明单点故障频繁
升级路径:
- 单机 Nginx 撑不住 → Nginx + Keepalived(水平扩展)
- Nginx + Keepalived 撑不住 → LVS + Keepalived + Nginx(引入 LVS 抗量)
- LVS 也撑不住 → 多 LVS 集群 + 云厂商 LB(水平扩展 LVS)
- 自研成本低于云厂商 LB 费用 → 自研 LB(参考 SLB/MGW/BFE)
不要"为了升级而升级"。日活 50 万的电商上 LVS 是合理,日活 5 万的内部 OA 上 LVS 就是浪费。
A10:流量调度的未来趋势是什么?
3 个明确方向:
- eBPF 替代 IPVS:eBPF 可以在内核更早的钩子点(XDP)处理包转发,比 IPVS 性能高 5-10 倍。Cilium 等项目已经在用 eBPF 替代 kube-proxy
- Service Mesh 接管 7 层:Envoy + Istio 在 K8s 内部已经能做精细流量治理,部分场景可以替代 nginx-ingress
- 云原生 LB:云厂商 LB 越来越智能,自带灰度、A/B 测试、流量镜像,未来自建 LB 的场景会越来越少
但这不意味着传统 LVS/Nginx 会被淘汰:
- 物理机 / 虚拟机场景仍是主流(很多公司没上 K8s)
- LVS 内核态转发的性能优势是物理规律,eBPF 只是更近一步
- 简单可靠的技术会长期存在(KISS 原则)
🛑 误区警示:追新 ≠ 用对
见过最离谱的:日活 10 万的电商,为了"用 Service Mesh"硬上 Istio。结果团队 3 个人花了 3 个月学 Istio,业务没提升,运维复杂度暴涨。
原则:用最熟悉、最稳定、最容易招聘运维的技术。新技术的红利期过了再用。