
排序算法是算法学习的"第一道关卡",也是面试最高频的考点之一。常见排序家族大致可以分为 O(n²) 简单排序、O(n log n) 高效排序、O(n) 特殊排序 三大类。这篇文章会带你用一张复杂度总览图 + 7 个核心排序的代码与动图串起整个知识体系。
为什么学排序? 排序看似简单,但它几乎是所有算法面试的"开胃菜"——它同时考察你时间/空间复杂度分析、稳定性判断、原地/非原地、递归/迭代等基础能力。更重要的是,很多高级算法(如二分查找、归并思想、Timsort)都建立在排序之上。
一、复杂度总览
一张图看懂 10 种常见排序的复杂度、稳定性、空间开销:
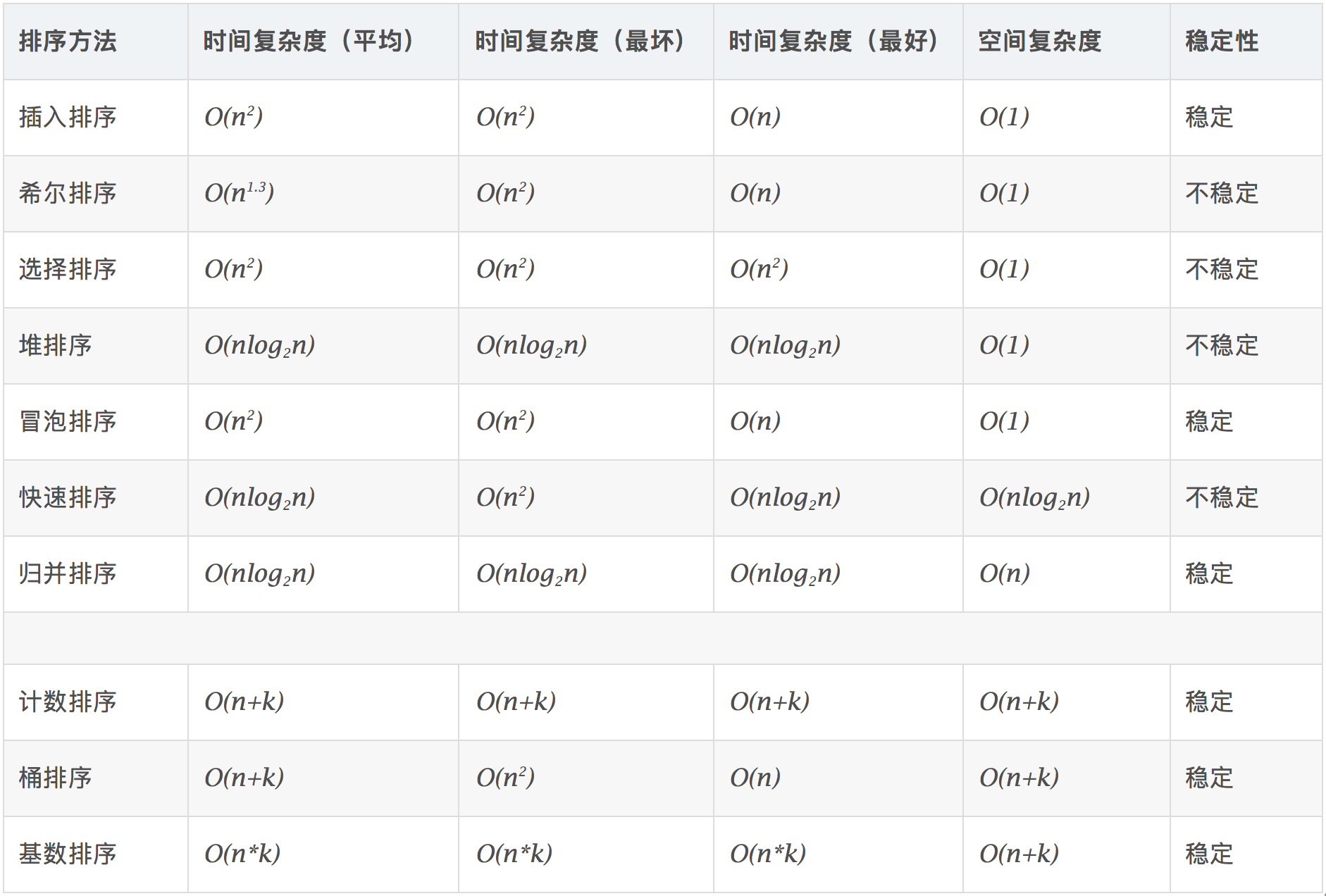
图源说明:上方图片来自原
常见排序.md文档的复杂度对比图,汇总了各种排序算法在最好/最坏/平均时间复杂度、空间复杂度、稳定性等关键维度上的表现,建议先记住这张图,再去深入单个算法。
速记口诀
| 类别 | 包含算法 | 时间复杂度 | 稳定性 | 一句话记忆 |
|---|---|---|---|---|
| 简单排序 | 冒泡 / 选择 / 插入 | O(n²) | 冒泡✓ 选择✗ 插入✓ | “三巨头”——最好写、最慢 |
| 高效排序 | 希尔 / 归并 / 快速 / 堆 | O(n log n) | 归并✓ 其他✗ | “工业级”——面试重点 |
| 特殊排序 | 计数 / 桶 / 基数 | O(n + k) | ✓ | “非比较”——特定场景起飞 |
| 高级混合 | Timsort / Introsort | O(n log n) | ✓ | 真实语言内置的排序 |
二、冒泡排序:入门第一课
动图演示:
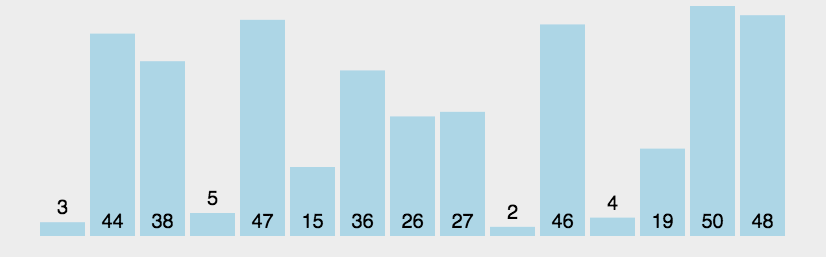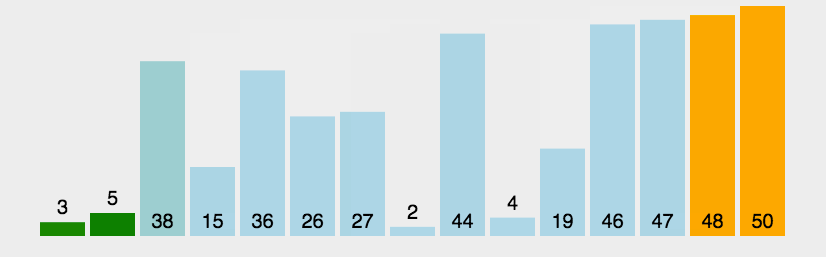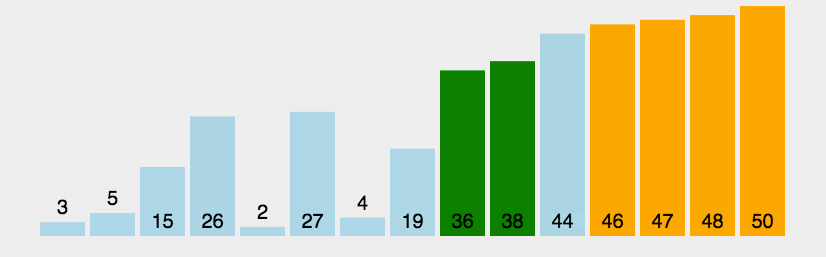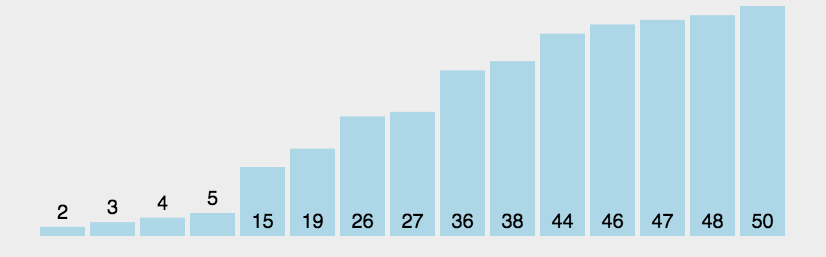
图源说明:上方 GIF 来自原
常见排序.md文档,演示了冒泡排序逐轮把最大元素"冒泡"到末尾的过程。
2.1 核心思想
像水里的气泡一样,两两比较相邻元素,如果前面的比后面的大就交换;这样一轮下来最大的元素一定会"浮"到最右边;重复这个过程 n-1 轮即可完成排序。
2.2 Python 实现
| |
2.3 关键点
- 稳定性:✓ 稳定(相等元素不会交换相对顺序)
- 原地性:✓ 原地排序(空间 O(1))
- 最好情况:O(n)(输入已经有序,加
swapped标志可提前结束) - 最坏情况:O(n²)(逆序输入)
- 为什么面试爱考:能引出"标志位优化"、"鸡尾酒排序(双向冒泡)“等延伸讨论
2.4 常见坑
- ❌ 内层循环写成
range(n)而不是range(n - 1 - i)——每一轮多比较已经排好序的尾巴 - ❌ 漏掉
swapped标志位——失去了"已经有序就提前结束"的优化 - ❌ 把”=“和”>“搞反——影响稳定性判断
三、选择排序:最直白但最慢
3.1 核心思想
每一轮从未排序部分找出最小值,放到已排序部分的末尾。
3.2 Python 实现
| |
3.3 关键点
- 稳定性:✗ 不稳定(交换会跨过相等元素)
- 原地性:✓ 原地
- 复杂度:无论输入如何都是 O(n²)(没有最好情况优化)
- 优势:交换次数最少(最多 n-1 次),适合"交换代价高"的场景(如写 SSD)
四、插入排序:数据越有序越快
4.1 核心思想
把数组分为"已排序区"和"未排序区”,每次从未排序区取一个元素,向前找到它在已排序区里的插入位置。
4.2 Python 实现
| |
4.3 关键点
- 稳定性:✓ 稳定
- 复杂度:最好 O(n)(已经有序)、最差 O(n²)(逆序)、平均 O(n²)
- 杀手锏:对近乎有序的数据极快——这就是为什么 Timsort(Python/Java 内置排序)会用它做"小块排序"(run)
五、希尔排序:插入排序的"跨度升级版"
5.1 核心思想
插入排序只能一步步挪动,效率差。希尔排序把数组按"间隔 gap“分成多个子序列,对每个子序列做插入排序;然后不断缩小 gap,重复;最后 gap=1 时退化为插入排序,但因为前面已经"基本有序"了,所以收尾很快。
5.2 Python 实现
| |
5.3 关键点
- 稳定性:✗ 不稳定(分组打乱了原顺序)
- 复杂度:平均约 O(n^1.3),取决于 gap 序列
- 现状:理论价值 > 工业价值,现实中基本被快速排序/归并排序取代
六、归并排序:分治的"教科书”
6.1 核心思想
分治法:把数组从中点分成两半,分别排序后合并(merge)。合并两个有序数组是 O(n),递归深度 O(log n),所以总复杂度 O(n log n)。
6.2 Python 实现
| |
6.3 关键点
- 稳定性:✓ 稳定(合并时用
<=而不是<) - 复杂度:始终 O(n log n),没有最坏情况
- 空间:O(n)(需要额外数组)
- 应用:Java
Arrays.sort()对对象数组的排序、Pythonsorted()内部走的就是归并的变体
七、快速排序:实战之王
7.1 核心思想
分治法:选一个"基准"(pivot),把数组分成"小于 pivot"和"大于 pivot"两部分,递归排序这两部分。平均 O(n log n),最坏 O(n²)(pivot 选得不好)。
7.2 Python 实现(最常见的 Lomuto 分区)
| |
7.3 关键点
- 稳定性:✗ 不稳定(分区会交换相等元素)
- 原地性:✓ 原地(O(log n) 栈空间)
- pivot 选取优化:三数取中(median-of-three)或随机 pivot 可以把最坏情况概率降到极低
- 现状:C/C++/Rust/Java 基础类型排序底层都用快排的变体(如 Introsort)
八、堆排序:原地 + O(n log n) 的"全能选手"
8.1 核心思想
利用二叉堆这种数据结构:先 O(n) 把数组建成大顶堆,然后不断把堆顶(最大值)换到末尾 + 下沉调整,循环 n-1 次。
8.2 Python 实现
| |
8.3 关键点
- 稳定性:✗ 不稳定
- 原地性:✓ 原地(真正的 O(1) 空间)
- 现状:常用于"内存极其受限“的场景(如嵌入式、操作系统内核)
九、核心要点与常见坑
9.1 核心 N 点
- 稳定性 vs 性能取舍:归并/插入/冒泡稳定但慢(O(n²) 或 O(n) 空间);快排/堆排/希尔快但不稳定
- 比较类 vs 非比较类:比较类有 O(n log n) 的理论下限;非比较类(计数/桶/基数)可以突破到 O(n),但需要数据有特殊结构
- 原地性:堆排是唯一稳定原地 O(n log n) 的算法;归并需要 O(n) 额外空间
- 真实语言内置排序都是混合策略——Timsort(Python/Java)= 归并 + 插入 + run;Introsort(C++/Rust)= 快排 + 堆排 + 插入
- “工业级默认"是快排/归并的变体,不要在生产里手写 O(n²) 排序
9.2 常见 M 个坑
- 冒泡忘了加
swapped标志——失去了"已经有序就提前结束"的优化 - 归并合并时用
<而不是<=——破坏稳定性 - 快排的 pivot 选最左/最右 + 已排序输入——直接退化为 O(n²),递归栈溢出风险
- 堆排的下沉边界写错——导致部分元素没参与调整
- 插入排序的内层 while 循环方向写反——会无限循环
- 混淆"时间复杂度"和"实际运行时间”——小数据量下 O(n²) 可能比 O(n log n) 更快(缓存友好、常数小)
十、选型速查
| 场景 | 推荐算法 | 理由 |
|---|---|---|
| 面试手写 | 冒泡/插入/快排 | 简单、能引出讨论 |
| 一般工业场景 | 用语言内置排序 | Timsort/Introsort 已经是最优 |
| 内存极小 + 大数据 | 堆排序 | 唯一原地 O(n log n) |
| 链表排序 | 归并排序 | 链表不适合随机访问,归并天然友好 |
| 数据基本有序 | 插入排序 | 几乎 O(n) |
| 大数据 + 整数 + 范围小 | 计数排序/桶排序 | O(n + k) |
| 字符串/车牌等定长字段 | 基数排序 | LSD/MSD 多轮分配 |
参考资料
- 《算法导论》第 2 章 / 第 6 章 / 第 7 章
- VisuAlgo - Sorting:在线可视化各种排序
- Timsort 原理:Python/Java 内置排序
- Introsort 原理:C++
std::sort内部用